D Ha et al. World Models. NeurIPS 2018 Oral paper homepage
- 이 paper는 pdf paper를 보기보다는 홈페이지를 읽으면 더 좋다.
Motivation
The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system. (Forrester, 1971)1
- 인간이 세상을 인식하는 것은 spatiotemporal 한 정보를 brain 내에서 abstraction함으로써 얻어짐
- 우리가 한 상태를 인식하는 것도 internal model의 future prediction에 govern됨
- RL에서도 past와 present, future을 잘 represent하는 것은 benefit이 됨
- 그러나 기존 RL 모델은 아주 작아서 이런 모델을 가지기 어려움
- 따라서 large world model과 small controller model로 구성된 agent를 구성함
Agent Model
- visual sensory component를 포함한 작은 agent를 구성함.
- memory를 가지고 future를 예측함.
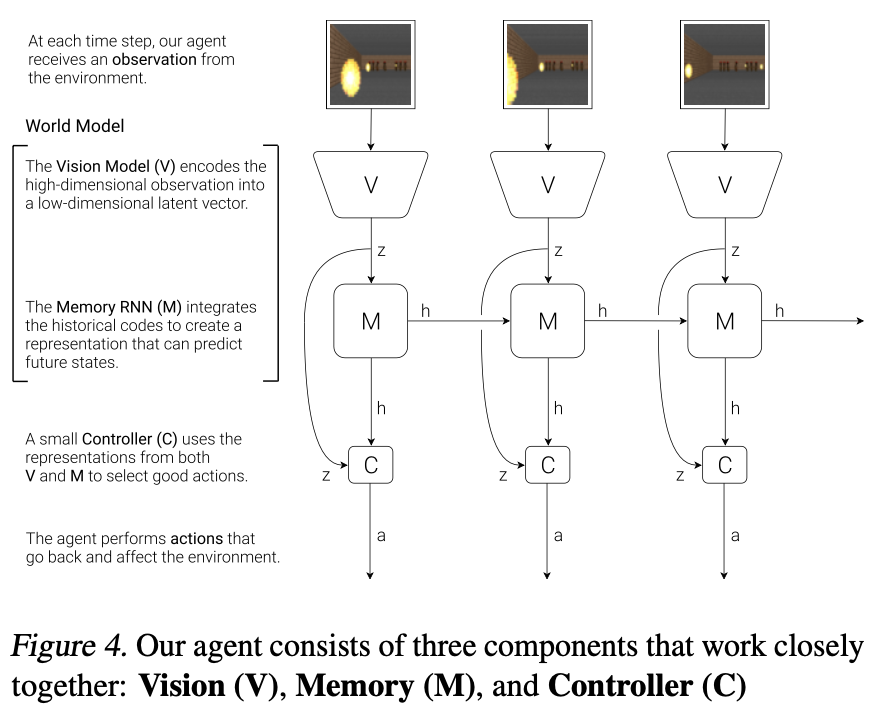
- component는 Vision (V), Memory (M), and Controller (C)로 구성됨.
- V로서 VAE를 사용함.
- M은 MDN (Mixture-Density Network) - RNN model임
- 현재 latent $z_t$를 보고 다음 latent $z_{t+1}$를 예측함.
- C는 action을 선택하여 reward를 maximize하는 모델이다.
- 여기서는 위의 논의에 따라 간단한 모델으로, simple linear model을 선택하였다:
- $$a_t = W_c[z_t h_t] + b_c$$
putting V,M, and C Together
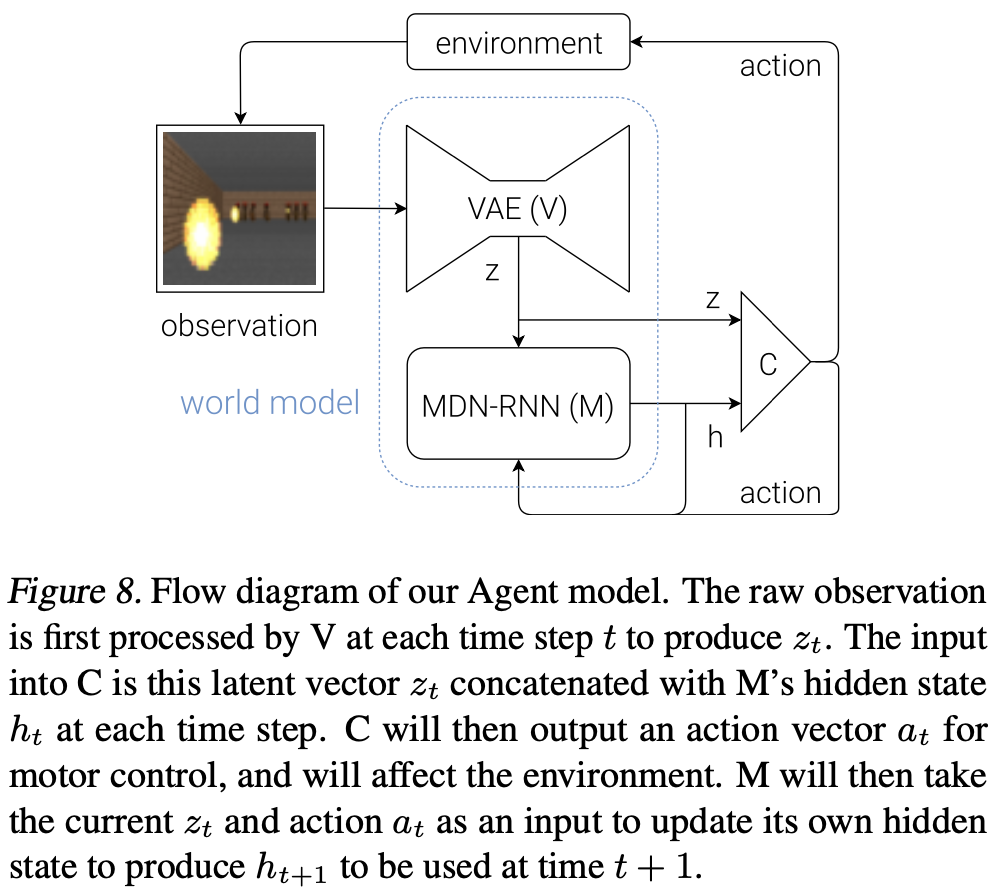
- 여기서의 V, M은 거대한 모델임. backprop으로 train됨.
- C는 작은 모델을 선택하였음. 이는 C가 unconventional way로 train될 수 있음을 의미하기도 함.
Car Racing Experiment
World Model for Feature Extraction
CarRacing-v0에서 실험함.- steering left/right, acceleration, and brake
- random 10,000 rollout을 만들고 dataset 획득
- world model V, M은 reward signal을 받지 않음.
- 단순히 compress, and predict
- C는 867 parameter를 가진 간단한 모델
Procedure
- 다음 step으로 수행됨.
- random policy에서 10,000 rollout을 획득함.
- VAE로 $z\in ℝ^{32}$로 encode하도록 train함.
- MDN-RNN을 $P(z_{t+1}|a_t, z_t, h_t)$를 model하도록 train함.
- Controller $C$를 $a_t = W_c[z_t h_t] + b_c$로 define함.
- CMA-ES로 expected cumulative reward가 maximize되도록 함.
| Model | Parameter Count |
|---|---|
| VAE | 4,348,547 |
| MDN-RNN | 422,368 |
| Controller | 867 |
Experiment Results
- 기존에도 driving 문제는 쉬운 것으로 알려져 있었음
- 따라서 handicap을 주어 $V$에만 접근하고 $M$에는 접근할 수 없도록 함.
- 즉, $a_t = W_cz_t +b_c$로 controller를 정의함.
Driving이 stable하지 않음.
- 이 경우 navigate는 가능하지만, wobble하고, sharp corner에서 miss track한다.
Full World Model (V and M)
- 위의 결과는 사실 당연함. 과거를 볼 수 없기 때문에 순간의 판단에만 의존함.
- 이 경우 역주행을 하는지는 알 수 없음.
Diving이 더 stable함.
Car Racing Dreams
- world model와 controller만 가지고도 다음 sequence를 계속 예측할 수 있다.
- 이를 이용하여 racing dream을 꿀 수 있다.
- homepage의 데모 참조
VizDoom Experiment
- VizDoom은 Doom-like 환경인데, agent를 공격하는 monster들로부터 fireball을 피하는 것이다.
- 20s 이상 생존시 solve한 것으로 인정되며 최대 60s 동작한다.
Training Inside of the Dream
- V는 latent vector를 학습함.
- M은 프로그래머가 만든 VizDoom과 동일하게 fireball을 쏘는 monster를 생성함.
- C는 control을 학습함.
- RNN이 게임 전체를 학습하여 C는 dream 안에서 train될 수 있음.
Cheating the World Model
- agent는 종종 adversarial policy를 학습함.
- virtual environment에서 M이 fireball을 생성하지 않으면 reward가 커짐.
- fireball이 생성되어도, C가 fireball을 extinguish하도록 움직이며 world model을 hacking함.
- 즉, C는 world model을 exploit할 수 있음.
- 그런 glitch는 real-world에는 존재하지 않을 수도 있음
- M은 probabilistic model이므로 real environment를 종종 follow하지 않음.
- C에게 M의 모든 hidden state를 넘겨줌.
- 이는 C가 M을 쉽게 exploit할 수 있는 기반이 됨.
- M이 exploitable하지 않게 하기 위해 M을 deterministic model에서 probabilistic model로 변환할 수 있음.
- $\tau$가 M의 randomness를 조절함.
- $\tau$가 매우 낮으면 deterministic LSTM과 유사해짐.
- 이 경우 mode collapse로 인해 environment가 fireball을 쏘지 않음.
- 이 경우 C는 아주 쉽게 수렴하지만, real-world의 harshiness에서는 fail함.
- $\tau$가 높을 수록 C는 M을 exploit하는 데에 어려움을 겪음.
- 그러나 너무 높을 경우 아무것도 배우지 못함.
| Temperature | Score in Virtual Environment | Score in Actual Environment |
|---|---|---|
| 0.10 | 2086 ± 140 | 193 ± 58 |
| 0.50 | 2060 ± 277 | 196 ± 50 |
| 1.00 | 1145 ± 690 | 868 ± 511 |
| 1.15 | 918 ± 546 | 1092 ± 556 |
| 1.30 | 732 ± 269 | 753 ± 139 |
| Random Policy Baseline | N/A | 210 ± 108 |
| Gym Leaderboard | N/A | 820 ± 58 |
Discussions
#1. 아름다운 논문임.
#2. 왜 controller는 작아야 할지? 여기서 VAE왜 M이 왜 world model의 역할을 하는지?
- 인식과 기억하는 부분 // 결정을 내리는 부분이 나뉘는 형태
- 만약 인식부를 훨씬 크고 방대한 dataset에서 pretrain할 수 있으면 controller는 world model의 inference만 가지고도 train할 수 있다.
C는 world model로부터 다른 task를 일종의 distillation하는 것
여기서 M이 exploitable했던 것은 V와 분리되어 있기 때문임.
- 왜?
- world model과 agent는 완전히 분리되어야 함. world model이 agent의 world 인식에 영향을 주면 안 됨.
- memory는 두 종류가 필요함. world-model memory와 agent memory
- agent memory가 world-model memory에 access하는 것은 exploit의 기반을 제공하는 것임.
- agent memory는 훨씬 더 작고, objective-centric way로 구성되어야 함.
- world model과 agent는 완전히 분리되어야 함. world model이 agent의 world 인식에 영향을 주면 안 됨.
- 즉, V-M을 합쳐야 함. M’-C도 합쳐야 함.
- 거대한 world와 그 안에서 결정을 내리는 보잘것없는 agent로 이루어져야 함.
- world model은 충실히 real-world를 reproduce하는 것에 그 목적을 두어야 함
- 그러나 미래 예측은 C에 주도권이 있어야 함. -> 이는 지금도 그렇다.
- 그렇다면 world model의 pretraining에서는 C가 없는데 그걸 어떻게 연결할 것인지?
- 둘의 연결성을 확보해야 한다.
- 이는 optical flow와 같은 경량화되고, motion-centric한 signal의 형태로 이루어져야 함.
- 왜?
World model의 개념은 video encoder의 학습 방식과 매우 유사함.
References
Forrester, Jay W. “Counterintuitive behavior of social systems.” Theory and decision 2.2 (1971): 109-140. ↩︎