VideoLLaMA 3
VideoLLaMA 3: Frontier Multimodal Foundation Models forImageand Video Understanding
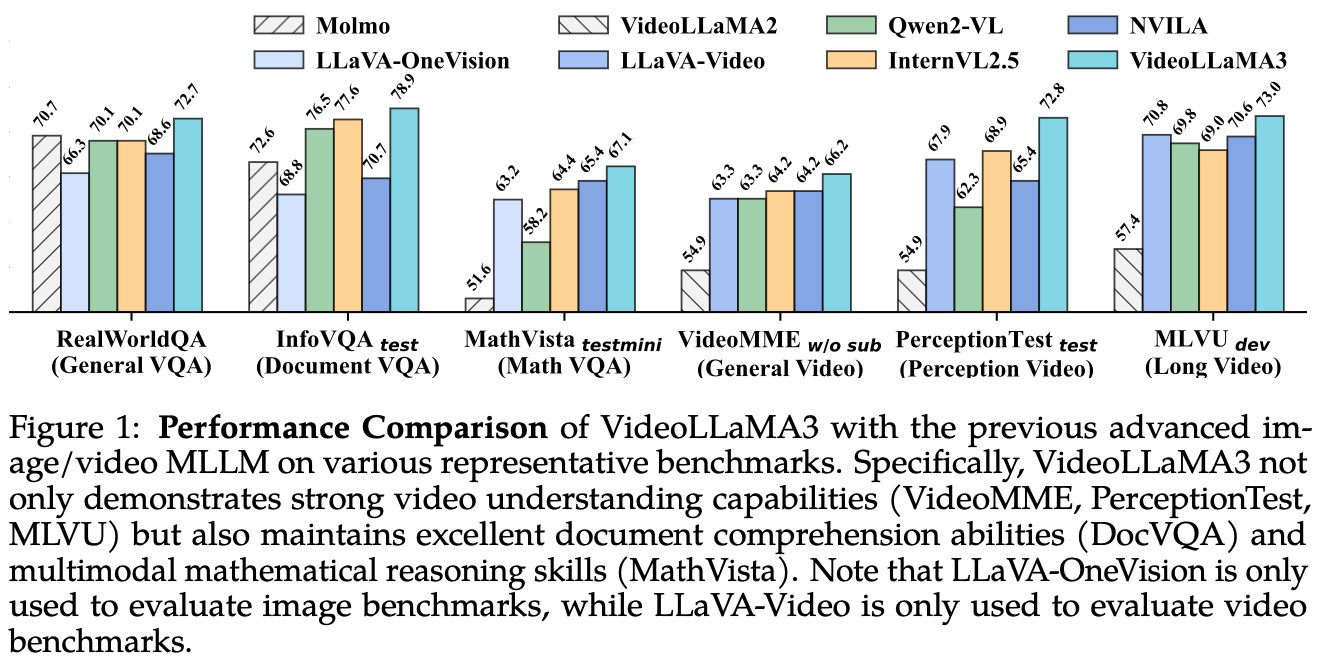
- 가장 큰 차이점을 vision-centric하게 finetune한 것으로 설명한다.
- vision-centric training paradigm은 다음으로 구성된다:
- Vision Encoder Adaptation: vision encoder를 LLM과 align
- Vision-Language Alignment: img-txt data에 대한 multimodal understanding
- Multi-Task Fine-tuning: interactive QA같은 downstream task에 대해서 finetune, video도 포함
- Video-centric Fine-tuning: video data로 training
- vision encoder enhancements
- dynamic resolution of images를 input으로 받도록 함
- vision encoder가 video token을 more compacted representation으로 받도록 함.
- 왜?
- fixed token이 아니라 variable하게 받을 수 있게 함.
- 이를 위해 fixed positional embedding을 RoPE로 바꿈
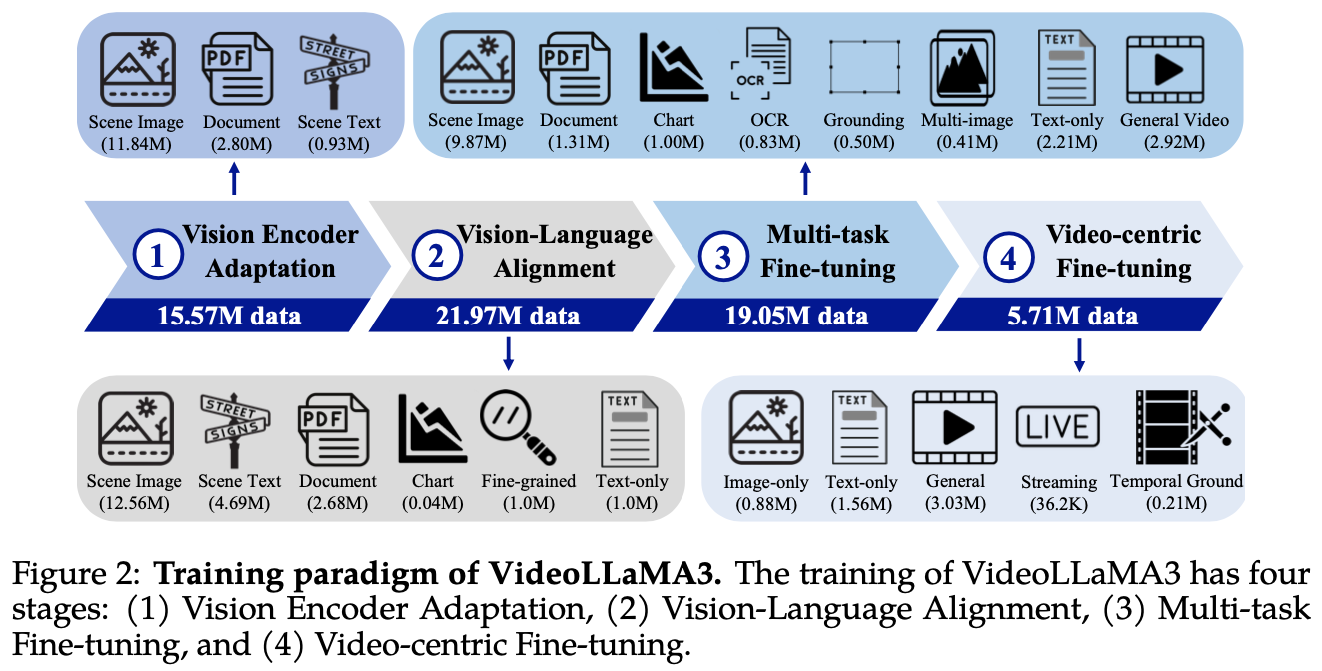
Method
- Any-resolution Vision Tokenization (AVT)
- Differential Frame Pruner (DiffFP)
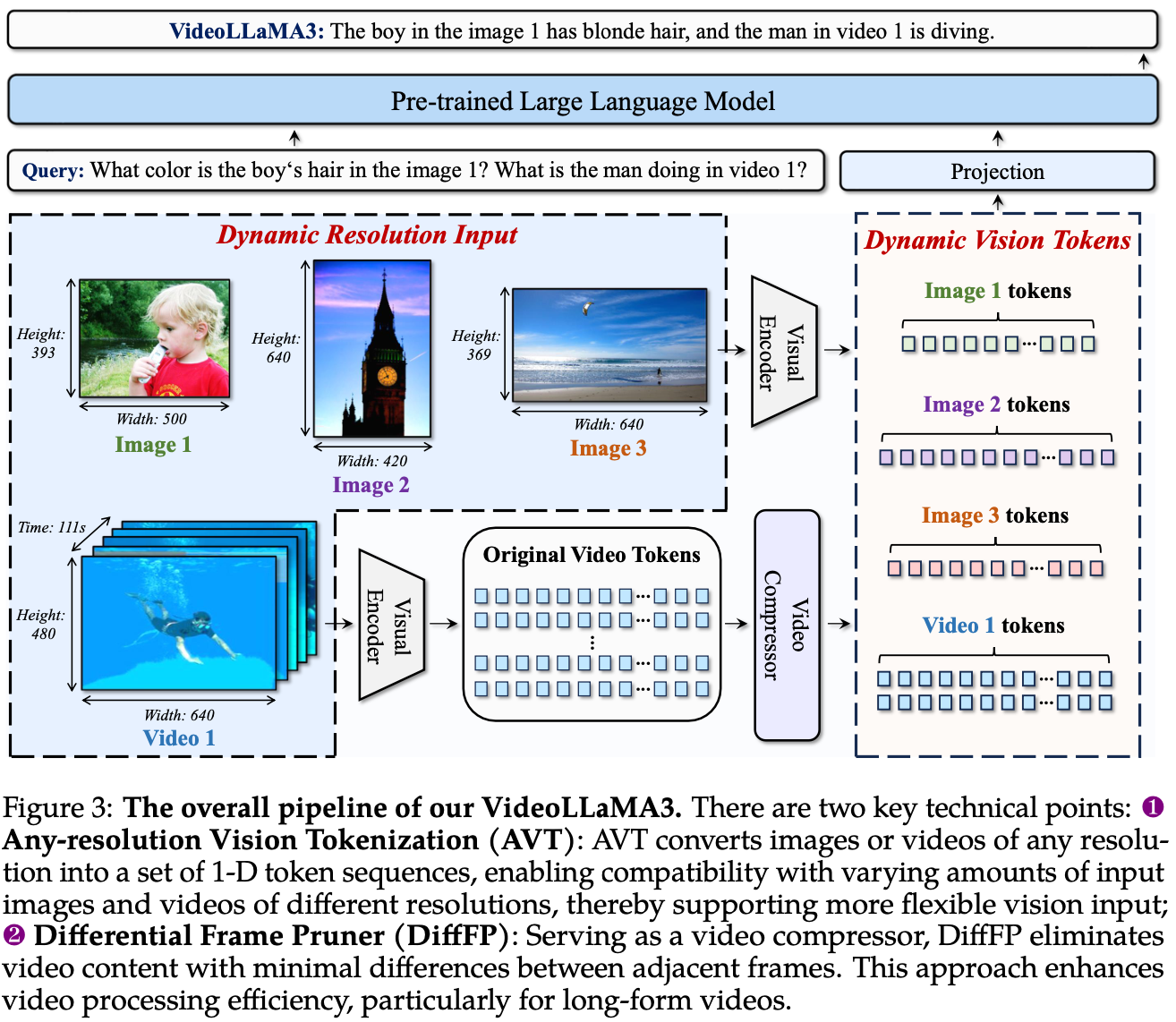
Any-resolution Vision Tokenization
- 기존에 LLaVA variant에서 쓰이던 AnyRes algorithm을 video로 확장
- ViT vision encoder를 scene image, document, scene test에 대해서 fine-tune (SigLIP)
Differential Frame Pruner
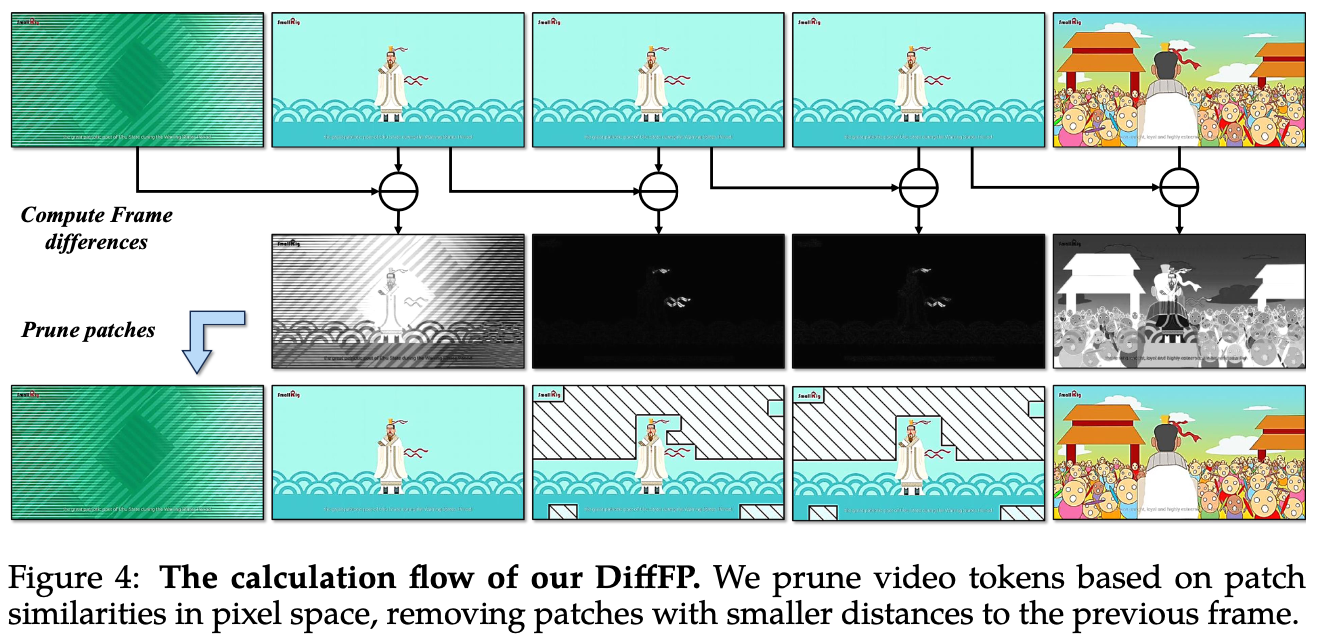
- video는 image에 비해 token이 너무 많고 redundant함
- computation demand를 reduce
- 각 image에 bilinear interpolation으로 2×2 spatial downsampling
- DiffFP로 video token을 prune함
- RLT1를 follow해서, pixel space에서 L1 distance를 비교
- predefined threshold=0.1 보다 낮은 patch는 prune
Construction of High-Quality Image Re-Caption Dataset
- VideoLLaMA3 training하는 데에 image re-caption dataset VL3-Syn7M을 만들었다.
- 이미지는 COYO-700M2에서 가져와서 다음 process를 거쳤다.
- Aspect Ratio Filtering: aspect ratio가 extreme한 값을 가지는 long wide image 제거
- Aesthetic Score Filtering: Aesthetic scoring model로 visual quality 측정하여 filtering
- Text-Image Similarity Calculation with Coarse Captioning: BLIP2로 initial caption을 만들고 CLIP으로 text-image sim score 낮은 것들 discard했다.
- Visual Feature Clustering: CLIP image feature로 kNN 써서 clustering하고, 각 cluster에서 fixed number of images 선택했다.
- Image Re-caption: InternVL2-8B랑 InternVL2-26B로 recaptioning했다.
- 결과적으로 7M image-captioning pair를 generate했다.
Training
- Model components
- vision encoder: SigLIP
- MLLM: Qwen2.5
- video compressor
- training process는 위에서 언급했듯이 4-step이다.
- Vision Encoder Adaptation: SigLIP을 dynamic resolution processor로 finetune, text encoder는 freeze
- Vision-Language Alignment: LLM 붙여서 full finetuning
- Multi-task Finetuning: image-video QA data로 instruction tuning함. 이때 video compressor도 추가함.
- Video-centric Finetuning: 모든 parameter를 열고 video, image에 대해 finetuning
Experiment
숫자는 해당 paper 참조. 숫자가 좋은 편은 아니다.
Discussion
- DiffFP가 좋은데 원래 RLT1의 문제점을 그대로 상속한다.
- 이게 patchwise로 pruning하는데 그때 pixel level에서 하는건 멍청한 semantic encoder가 개입되지 않아서 좋은 점이다.
- 다만, 그냥 background가 바뀌는 화면 전환 상황에서는 쓸데없이 token을 많이 가져간다는 문제가 있다.
- 이 겨웅에는 Chat-UniVi처럼 things하고 stuff정도만 rough하게 구분해서 stuff는 token merging해도 될 것 같다.
- pruner가 별로라서 pruner를 train해봐도 될듯
- frame 간 dependency는 계산하지 않고 그냥 pruning + concate한다.
- video 내에서 frame 간 순서는 어떻게 파악하는지
- MVbench같은 곳에서 InternVideo2.5같은 video 전문 모델보다 훨씬 못한다.
- temporal dependency를 제대로 이해할 수가 없는 구조다.
- RLT는 개선할 점이 많이 보인다.
- dense한 태스크에는 쓸 수가 없다.
References
Rohan et al. Don’t look twice: Faster video transformers with run-length tokenization. NeurIPS, 2024. ↩︎ ↩︎
Minwoo et al. Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/coyo-dataset, 2022. ↩︎