VideoChat variants
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
publish: arXiv 2501
- Hierarchical video token Compression (HiCo) method 제안
- multi-stage strong-to-long learning scheme 제안
- LongVid dataset 제안, Mulit-Hop Needle in A Video Haystack 제안
- VideoChat-Flash 제안
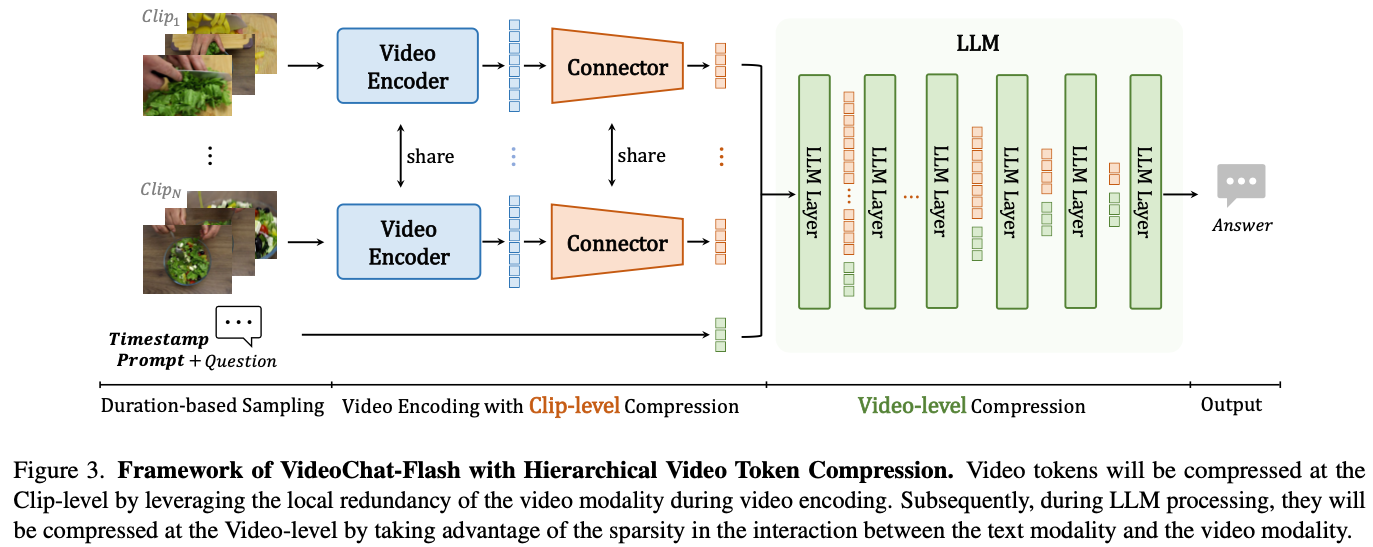
Method
HiCo: Efficient Long Video Modeling
- HiCo는 video context compression을 위한 방법
- 두 단계로 구성:
- Clip-level compressions during the encoding of long videos
- Video-level compression within the context interaction in the LLM
Duration-based Sampling
- duration $D$인 raw video에서 $T$ frame을 sampling
- short video는 dense sampling, long video는 sparse sampling $$T = \min (T_{\max}, \max (D,T_{\min}))$$
- sampling density $φ$는 다음으로 구성 $$φ(T,D) = \frac{T}{D} = \frac{\min(T_{\max},\max(D,T_{\min}))}{D}$$
Timestamp Prompt
- timestamp를 위해 새로운 module을 추가하지 않음.
- “The video lasts for N seconds, and T frames are uniformly sampled from it.” prompt 사용
- 이것만 해도 input video의 temporal grounding을 위한 timestamp를 인식하기는 충분하다고 주장 (Tab. 1 참조)
Spatio-Temporal Compression Encoding for Clips
- video를 $N_c$개의 equally sized clip으로 나눈다.
- clip을 video encoder로 spatiotemporal attention해서 encode한다.
- similar token을 merge한다.
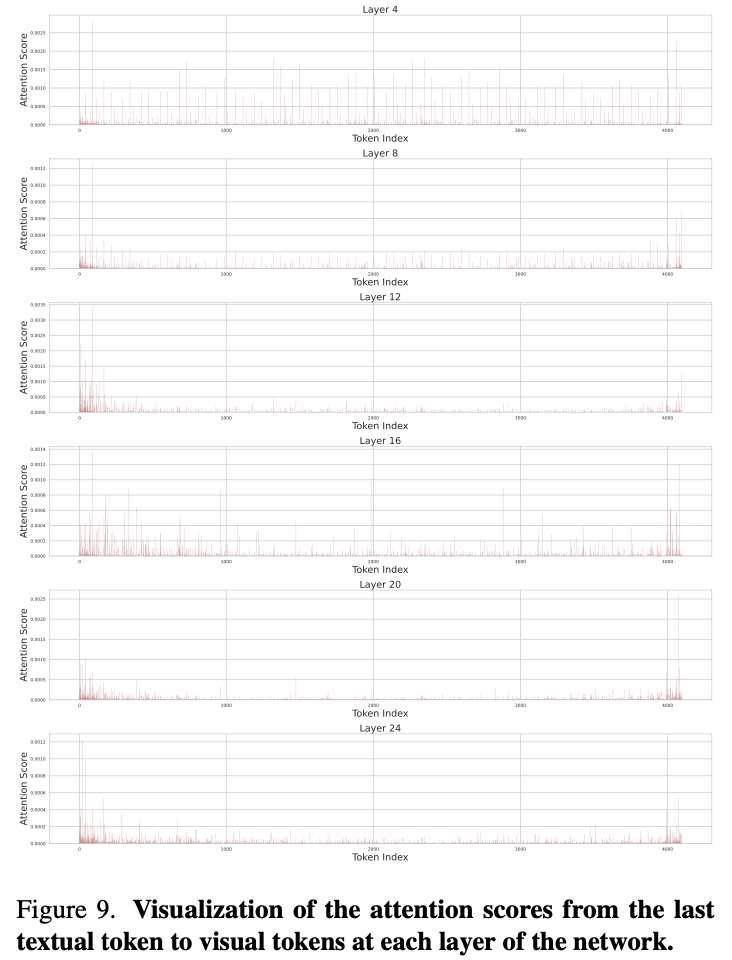
Progressive Visual Dropout in LLM
- clip level로 compression한 이후에도 long video의 visual redundancy는 남아있음.
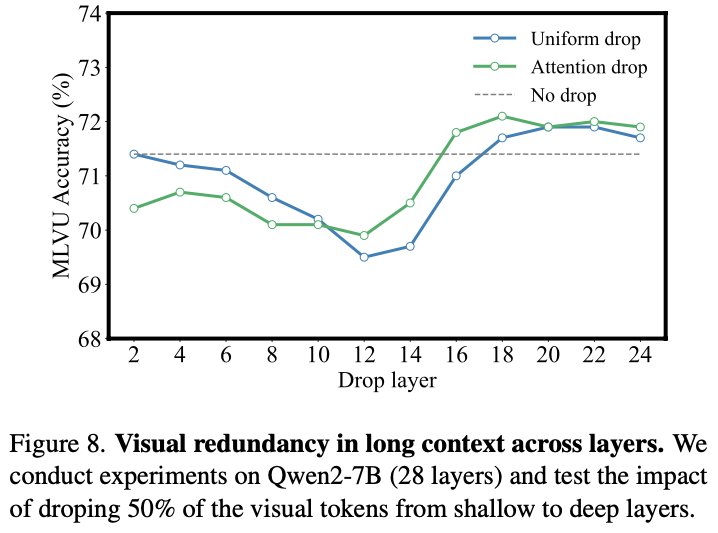
- 1 2 에서 대부분의 visual token은 drop됨을 확인함.
- 반면 long video context를 처리할 때에는 shallow layer에서 entire context를 처리하고 deep layer에서는 certain local moment를 확인함 (Fig. 9 참조).
- 이를 위해 shallow layer에서 uniform하게 적은 수의 video token을 drop함 (Fig. 8 참조).
Large-scale Corpus for Long Video Training
- long video에는 video-text pair의 high quality data가 부족하다고 함.
- long video instruction tuning dataset인 LongVid 제안
- 114,228 long video
- 3,444,849 QA pairs across 5 tasks
- various source에서 가져옴.
Multi-stage Short-to-Long Learning
- Stage 1: Video-Language Alignment
- VE, LLM freeze
- compressor, MLP train
- 0.5M img-txt pairs, 0.5M short vid-txt pairs with 4fps
- Stage 2: Short Video Pre-training
- short vid-txt pairs에 대해 pretraining
- 3.5M img, 2.5M short vid-txt pairs
- Stage 3: Joint Short & Long Video Instruction Tuning
- instruction tuning
- 1.1M img, 1.7 short videos, 0.7M long videos (1m-1h long)
- Stage 4: Efficient High-Resolution Post-finetuning
- input resolution을 224 to 448로 늘림
Multi-Hop Need in A Video Haystack
- 3 4 에서는 Needle in a Video Haystack (NIAH-Video)로 long video understanding을 평가함.
- 이는 long video 안에 image를 삽입하고 이에 대해 대답하는 질문
- 삽입한 image의 information leakage와, long video understanding을 정확히 평가할 수 없다는 한계가 있음.
- 새로운 방법인 Multi-Hop Needle in a Haystack (MH-NIAH-Video)를 제안
- Fig 4와 같이 중간에 삽입된 image에 text clue를 넣고 그걸로 다음 image를 찾아 대답하도록 하는 방법
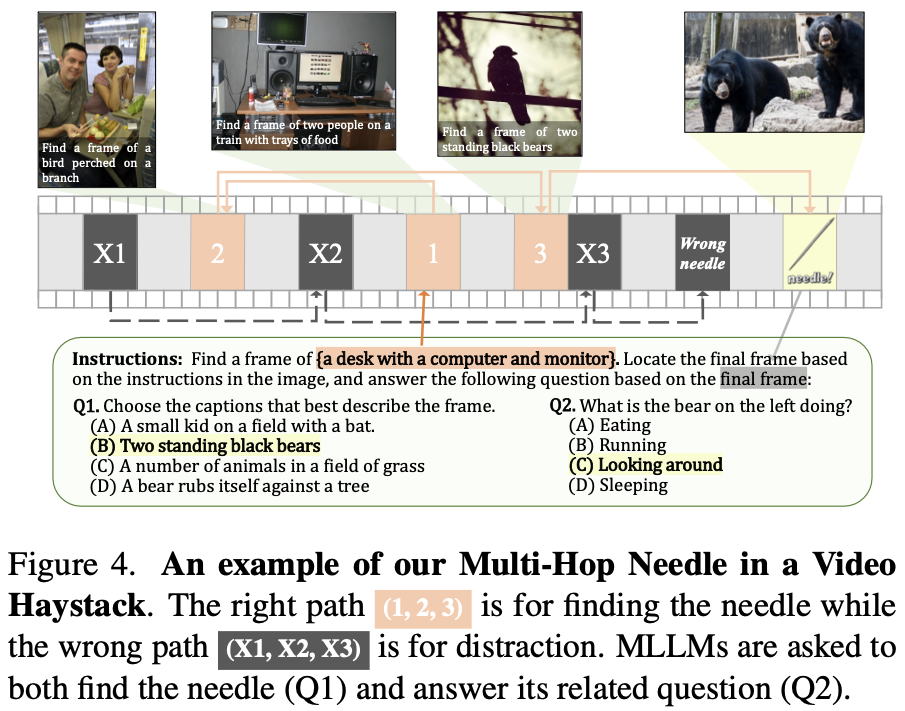
- Fig 4와 같이 중간에 삽입된 image에 text clue를 넣고 그걸로 다음 image를 찾아 대답하도록 하는 방법
Experiments
Implementation Details
- video encoder: UMT-L
- connector: MLP
- LLM: Qwen2-7B
Discussion
- NIAH-Video나 MH-NIAH-Video나 너무 이상한 방법이다.
- 저런 setting이 실제 long video understanding하고 무슨 상관이 있는지?
- 왜 잘할까?
- temporal order나 temporal information도 잘 이해할까?
- 중간중간 잠깐 보는 건 잘함.
- 근데 이건 지금의 video 이터셋들이 긴 시간의 순서를 잘 이해하지 못해도 잘 풀게 되어있는거 아닌가
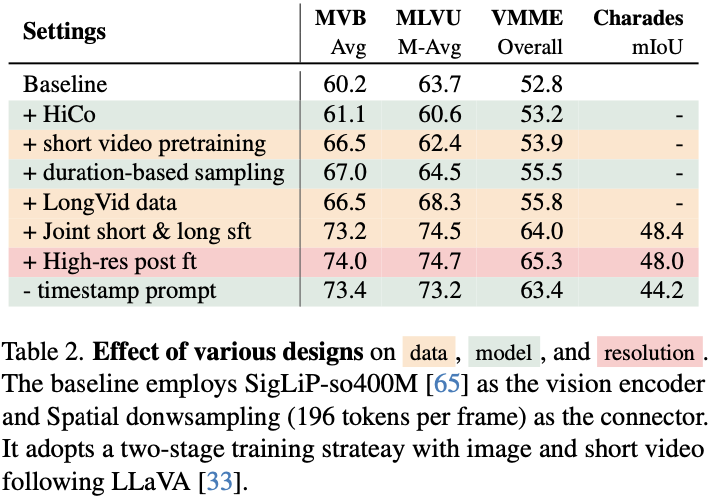
- table 2를 보면 method에서 이득본게 많다기보다는 data 많이 끌어다가 쓴 게 critical한 듯.
- architecture는 optimal한건지는 잘 모르겠다
- video를 uniform하게 쪼개서 붙이는 방식?
References
Jieneng et al. Llavolta: Efficient multi-modal models via stage-wise visual context compression. NeurIPS 2024. ↩︎
Liang et al. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. ECCV 2024. ↩︎
Fuzhao et al. Longvila: Scaling long-context visual language models for long videos. arXiv 2024. ↩︎
Peiyuan et al. Long context transfer from language to vision. arXiv 2024. ↩︎