최근 GRPO의 성공 이후로 vision model에도 이를 적용한 approach들이 연구되고 있다. 이에 대해 최근 제안된 방법론들을 확인한다.
VideoChat-R1 (arXiv 2503)
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
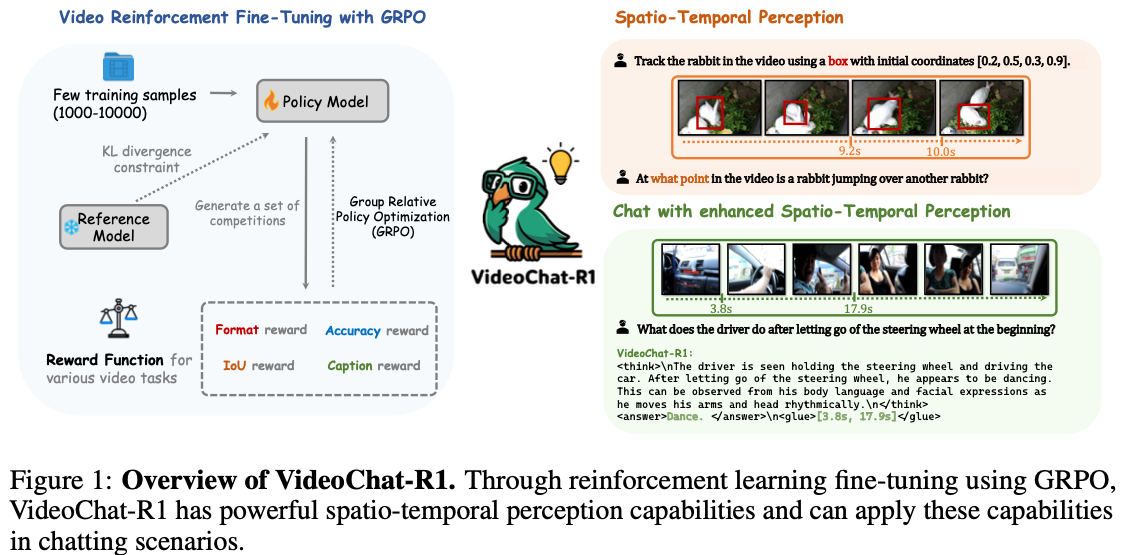
특별히 motivation이라고 할 만한 것은 없고, 그냥 GRPO 1 를 video에 써봤다 정도이다. 다음을 finding으로 주장한다:
- Reinforcement fine-tuning is data-efficient for enhancing models on specific tasks without sacrificing original capabilities
- Through joint reinforcement fine-tuning on multiple spatio-temporla perception tasks, suggest VideoChat-R1.
Method
Spatiotemporal Rewards of Video MLLM in GRPO
Format reward
- $R_{format}$은
<think>...</think>나<answer>...</answer>format에 대한 reward이다. - match되면 0, 그렇지 않으면 1
IoU reward in spatiotemporal perception
- temporal grounding이나 object tracking의 경우
- $R_{IoU}$는 IoU로 정의된다.
Accuaracy reward in classification
- video cpationing이나 open-eneded outputs의 경우
- LLM이 정답을 judge함.
- Qwen2.5-72B 사용
- gt에 있는 event들은 pred가 잘 entail했는지 확인
- $R_{recall} = Recall_{event}(C_{pred}, C_{gt})$
Reward Function and Training
- Reward Function
- $R_{st} = R_{format}+R_{IoU}$ – temporal grounding, object tracking
- $R_{qa} = R_{format} + R_{accuarcy}$ – VQA, video quality assessment
- $R_{gqa} = R_{format}+R_{IoU}+R_{acc}$ – grounding QA
- $R_{cap}=R_{format}+R_{caption}$ – video captioning
Experiment
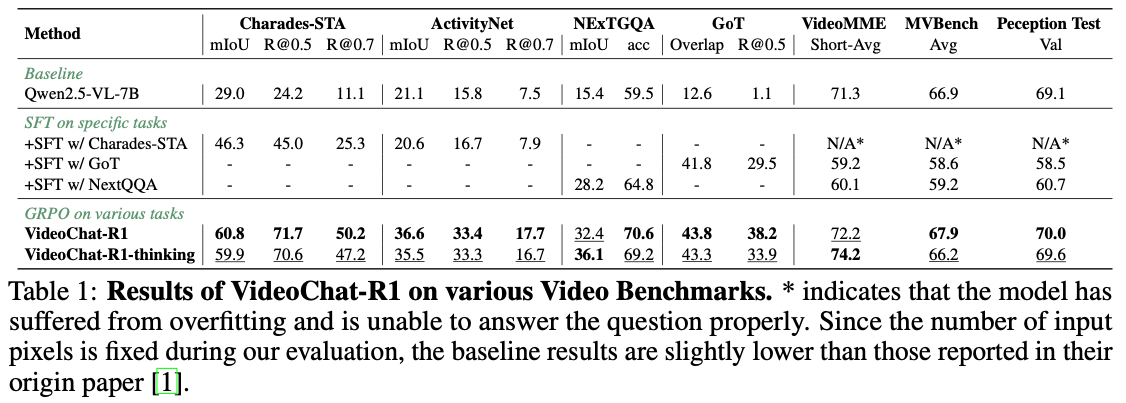
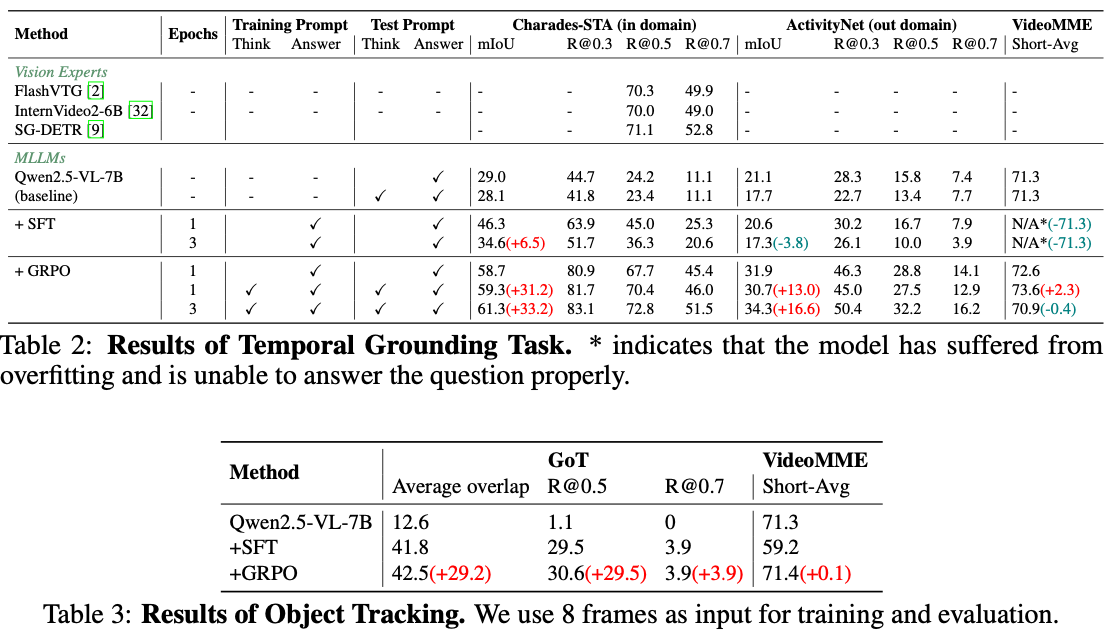
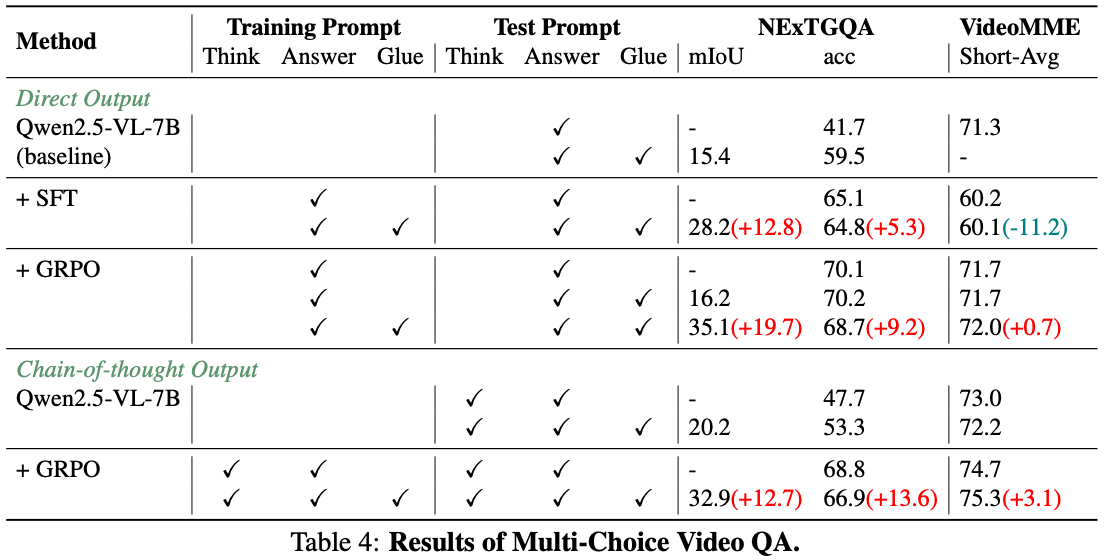
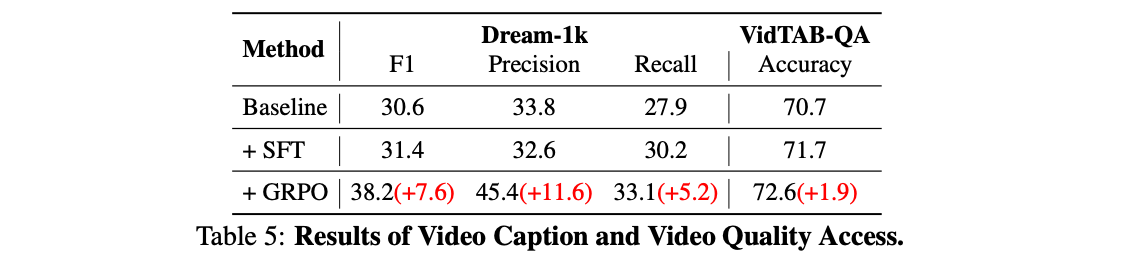
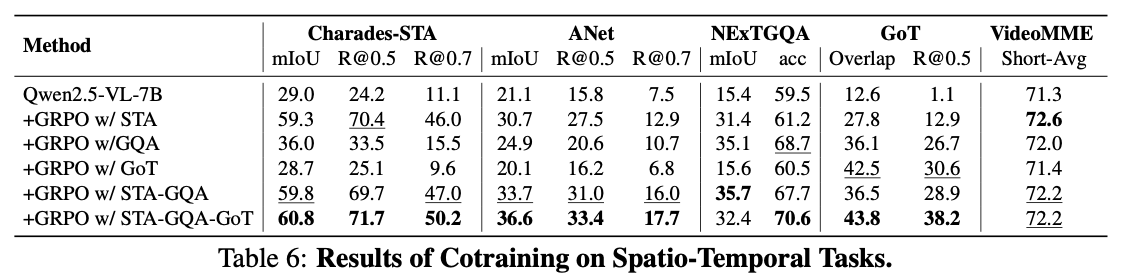


Discussion
- 숫자는 좋아보이지만, table 내의 비교는 fair하지 않음.
- 기존의 video MLLM과 비교하면 Charades-STA 정도만 개선됨.
- 이는 아마도 temporal localization이 vision token보다는 reasoning를 통해 더 잘 해결될 수 있음을 나타내는 것으로 보임.
- 다른 task는 video를 더 잘 보는 것이 중요함.
- 지금의 reasoning formatting은 지나치게 language-centric함.
- vision 문제를 풀기에 적합한 방식이 아님.
Video-R1 (arXiv 2503)
Video-R1: Reinforcing Video Reasoning in MLLMs
Motivation
original GRPO는 video의 temporal signal을 reward하지 않음.
- Fig. 1과 같이 temporal information을 이해하지 못할 수 있음. → Discussion 1 참조
video 내의 reasoning에 대한 data가 부족함.

Contribution
- GRPO의 temporal reasoning에 대한 extension인 T-GRPO을 제안
- image-based reasoning data 도입
- Video-R1-COT-165k for SFT cold start
- Video-R1-260k for RL training
- 이를 활용한 Video-R1 모델 제안
Method
Dataset
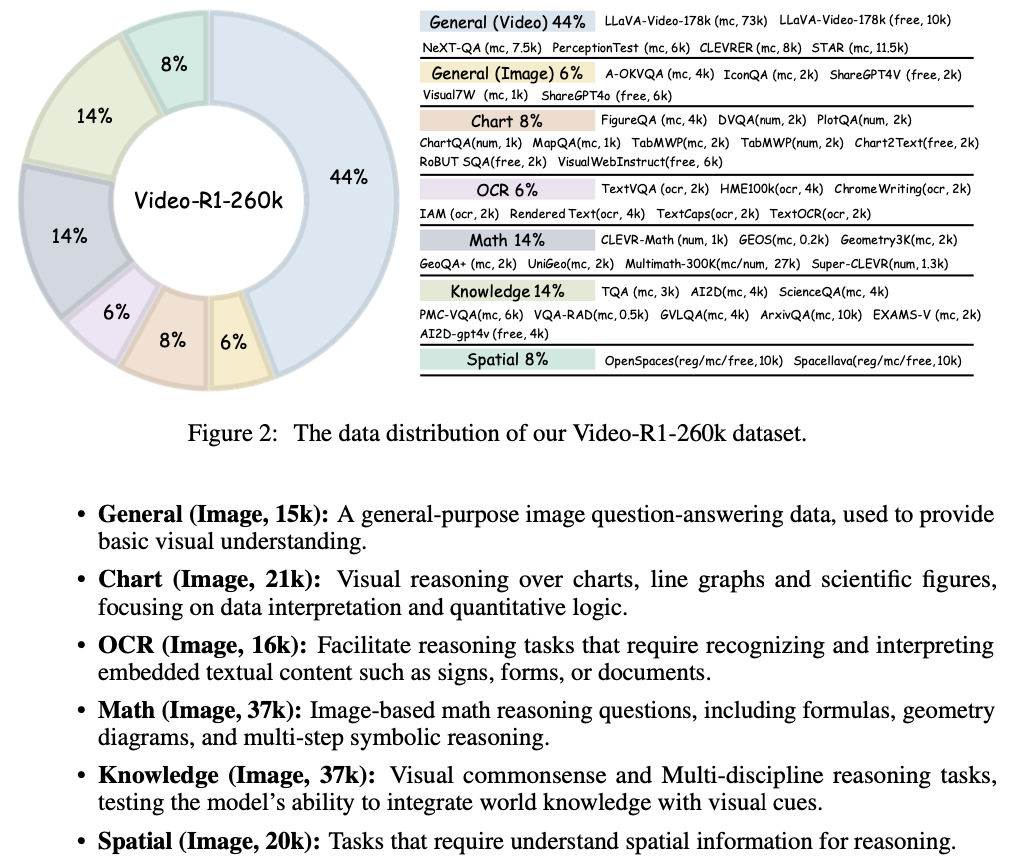
- dataset에 Qwen-VL-72B로 COT rationale을 만듦
- Video-R1-260k 제작
- 일부 filtering하여 cold-start SFT를 위한 Video-R1-COT-165k 제작.
T-GRPO
- 핵심 아이디어는 two different order로 frame을 제공했을 때의 결과를 비교하는 것.
- temporally ordered sequence
- randomly suffled sequence
- 각 group에서의 response를 각각 $\{o_i\}^G_{i=1}, \{\tilde {o_i} \}^G_{i=1}$ 라고 하자.
- $p, \tilde p$를 each group의 correct answer의 proportion이라고 하자.
- reward $r_t$는 $p>μ \cdot \tilde p$일때 $α$, otherwise $0$.
- $α=0.3, μ=0.8$는 hyperparameters
- 즉, video가 temporal order로 보여졌을 때 더 잘 하도록 encourage함. → Discussion 2 참조
Experiment
- Qwen2.5-VL-7B-SFT로 train
- train은 1 epoch of SFT와 1k RL step
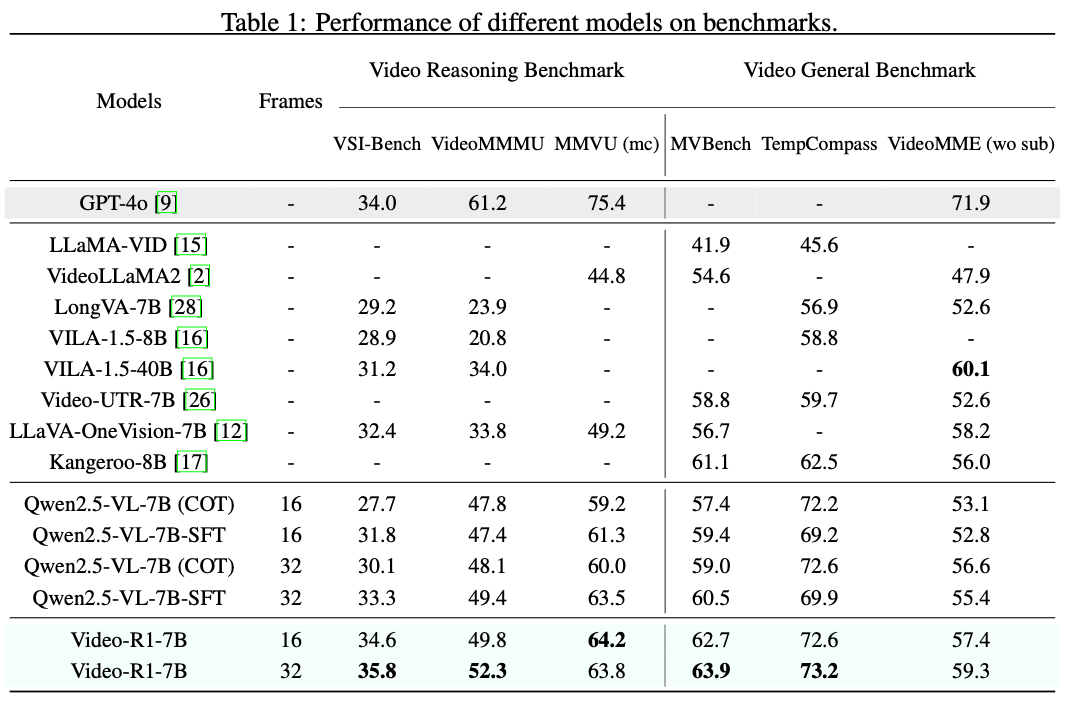
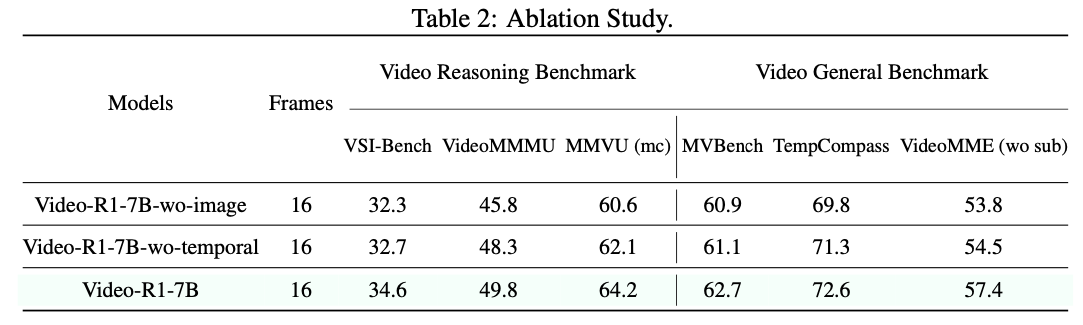
Discussion
- #1 video encoding 과정에서 temporal information이 들어가는데, 이걸 전혀 모르는 듯이 reasoning하는 것은 매우 이상하다.
- language와 연결이 안 되어 있는 거라면 기존 Video MLLM 모델에서 prompting할 떄 앞에 video meta 정보를 prompt에 넣는데, 이를 활용해도 좋을 듯.
- #2 디자인이 아주 이상하다.
- Qwen2.5-VL에서 video는 RoPE로 temporal encoding이 들어간다.
- 왜 encoding이 반영이 안되는지 판단하는게 먼저임.
- reasoning을 잘하게 하는 방식?
References
Z Shao et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. CoRR 2024. ↩︎