Does Spatial Cognition Emerge in Frontier Models?
Abstract
- Suggest SPACE benchmark
- A benchmark to evaluate spatial cognition abilities of frontier model
- It shows that contemporary frontier models are far from achieving the spatial recognition abilities of animals
Motivation
- Spatial cognition refers the ability of animals to perceive and interact what they see visually
- They build internal representation of the world to navigate and manipulate
- It’s mentioned in the World Models
- Spatial cognition is recognized to be linked to embodiment
- However, current frontier models are trained on disembodied modalities such as text, images and video
- Therefore, what this paper want to see is to check such models have emerged spatial congition abilities
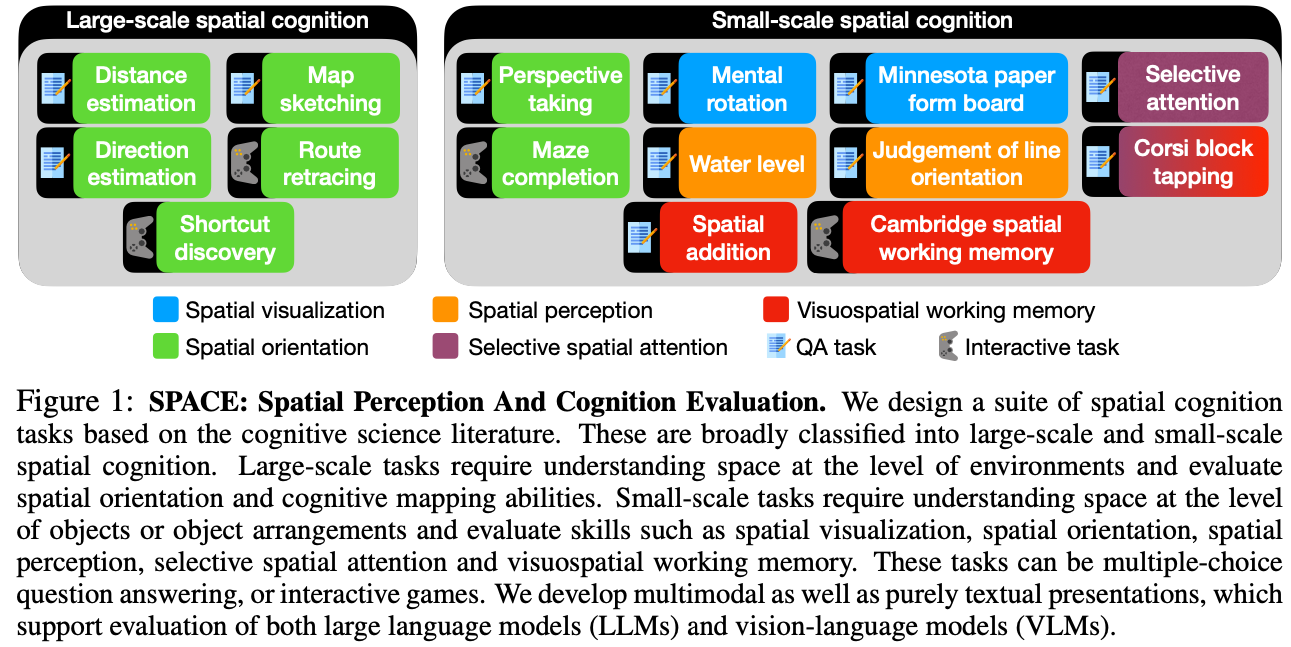
- They devided spatial recognition tasks into two sub-categories
- Large-scale spatial cognition
- In this task, the model is familiarized with an environment and is then asked the estimate quantitative values
- Small-scale spatial cognition
- about model’s ability to perceive, imagine and mentally transform objects in 2D or 3D
- Large-scale spatial cognition
SPACE: a benchmark for Spatial Perception And Cognition Evaluation

Large-Scale Spatial Cognition
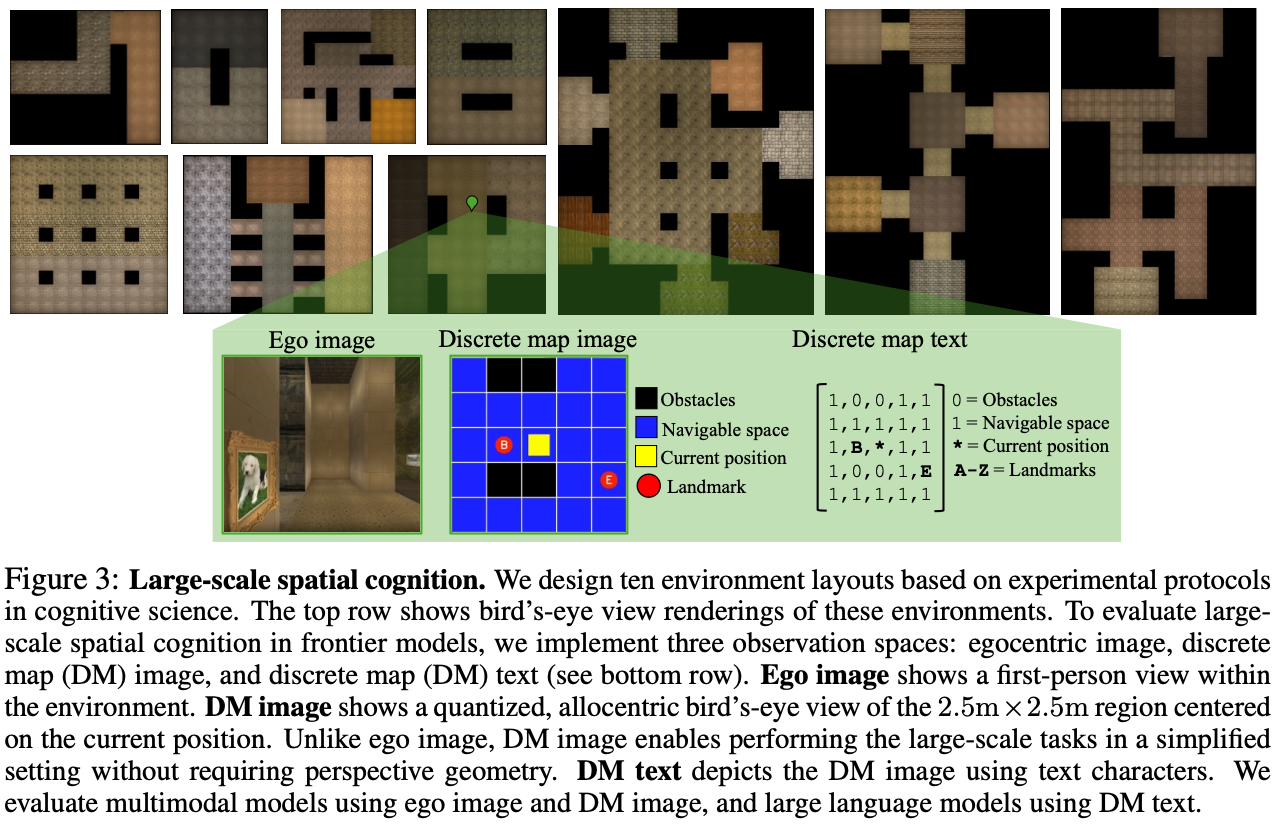
- This task consists of two stages
- Familiarize the model with an environment by showing a video walkthrough
- In text-only models, the ‘video walkthrough’ is passed as a matrix (See Fig. 3)
- Evaluate the model with five tasks below:
- Direction estimation
- determine the direction from a benchmark A to another benchmark B
- this task is formulated as a multi-choice QA
- Distance estimation
- determine the straight-line distances from one landmark to all other landmarks
- multi-choice QA with four options
- Map sketching
- draw a map of the environment that contains the start, goal and landmark positions
- multi-choice QA with four options
- Route retracing
- retrace the route shown in the video from the start to the goal
- interactive task – the model gets next observation after taking an action
- Shortcut discovery
- The goal is to discover a shortcut
- interactive task
Small-Scale Spatial Cognition
- tasks to evaluate models’ ability to perceive, imagine and mentally transform objects of shapes
- TL; DR: please refer fig. 2
Experiment
- Experiments are carried out on GPT-family models, LLaVA etc.
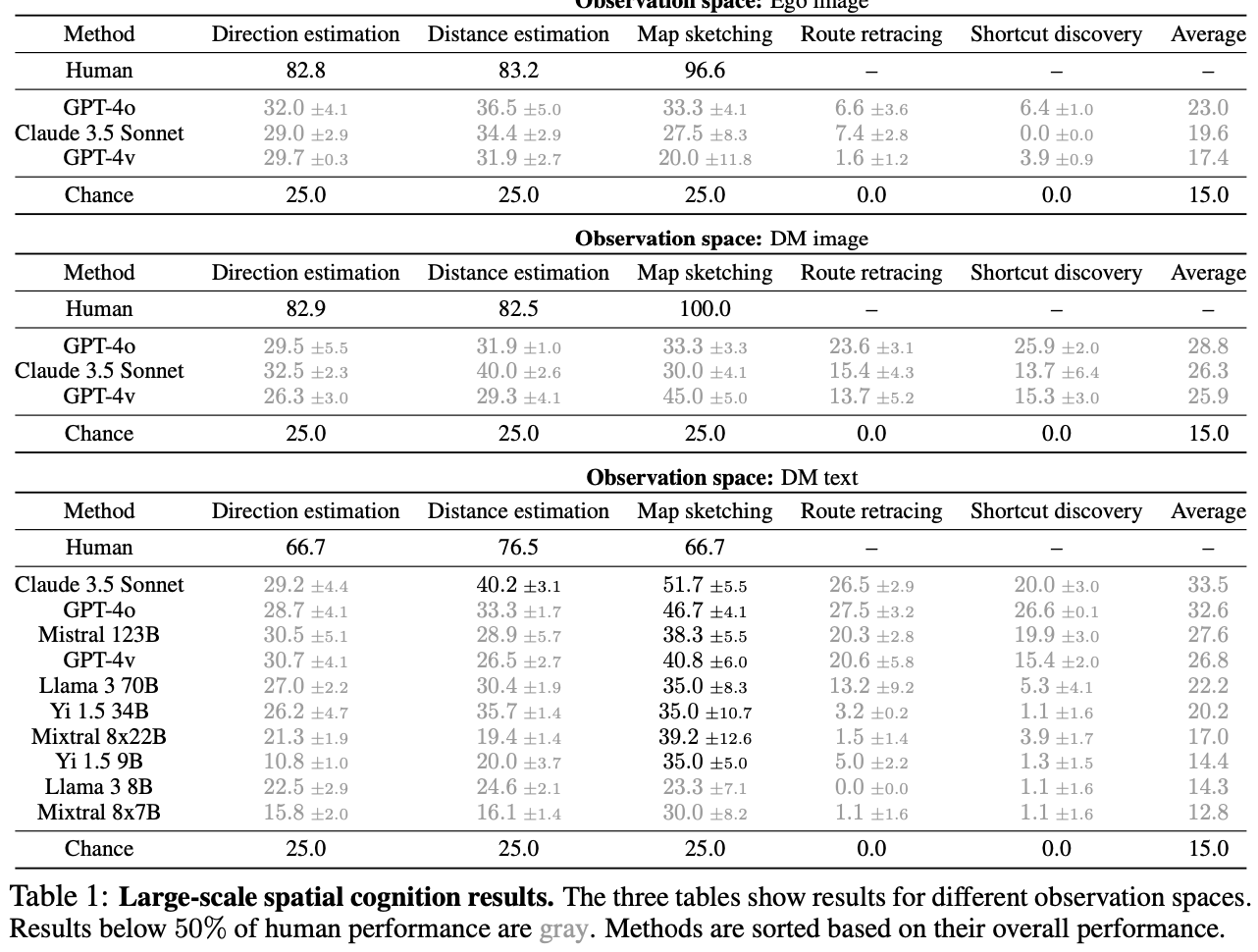
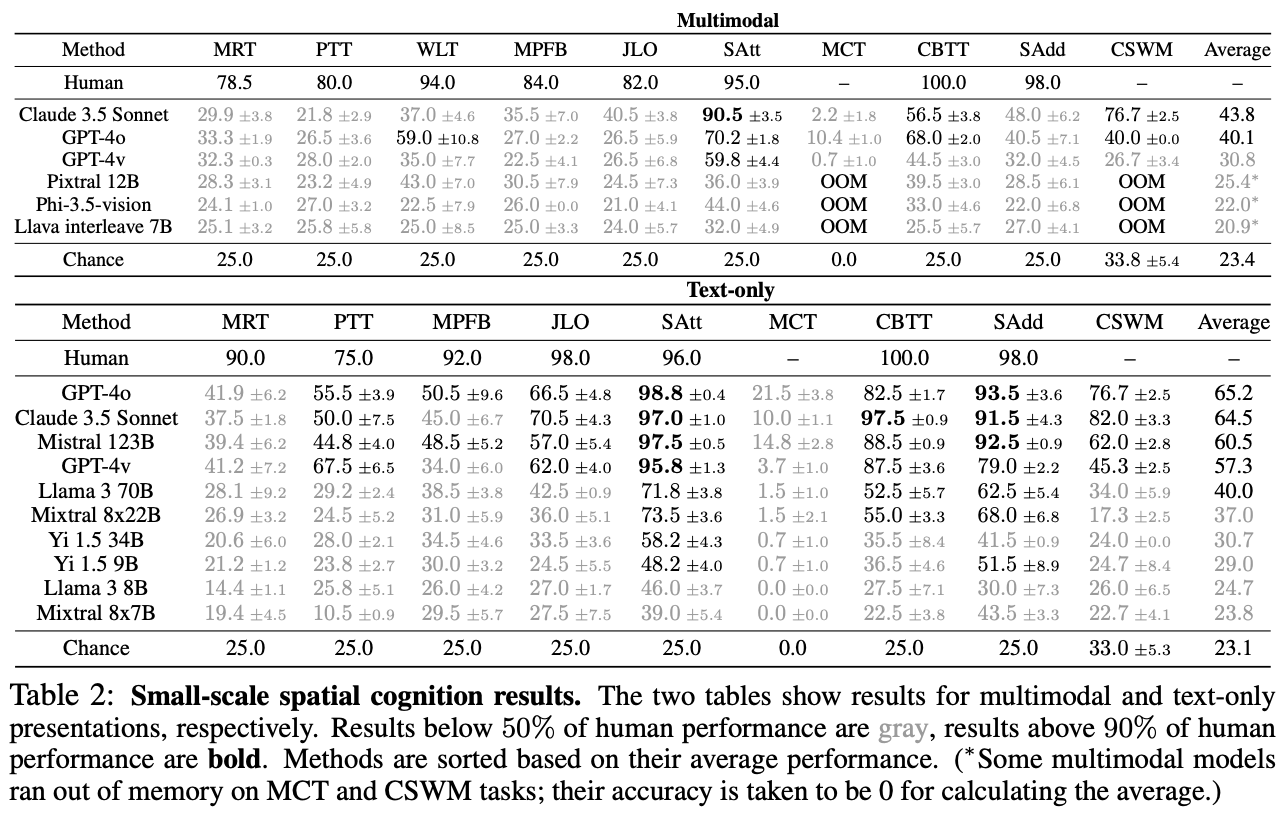
Discussions
- Authors said that contemporary models do not possess same kind of intelligence as humans and animals
- Models still fail to cognize the visual inputs
- Models tends to fail on more visual-centric tasks, such as MRT and MCT
- and they have a tendency to get a good performance on text-centric vision tasks, such as SAtt and SAdd