InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
published: Jan 2025
Abstract
- Long and Rich Context (LRC)를 통한 video MLLM 제안
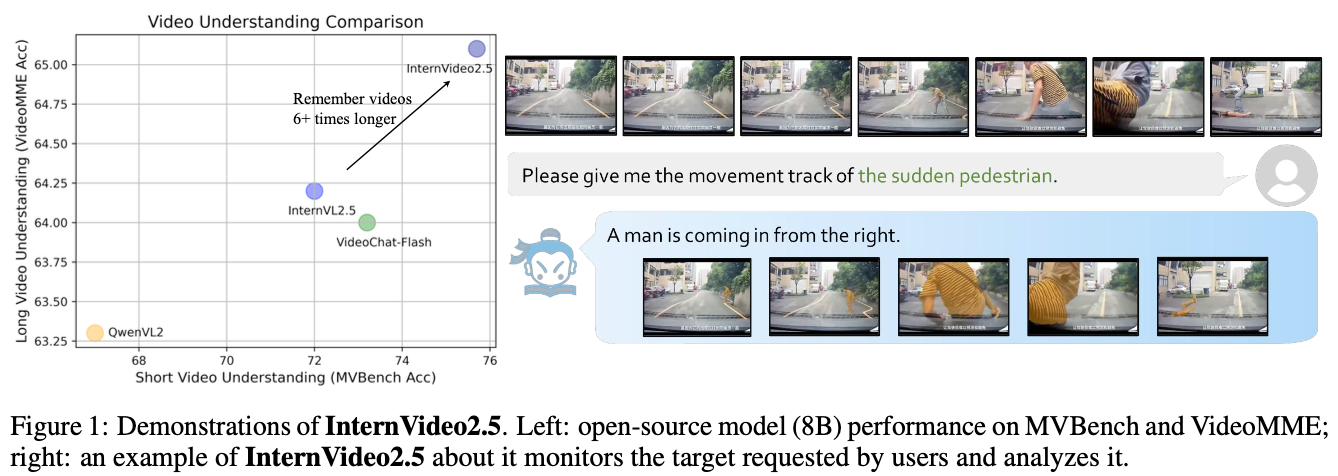
- InternVL2.5보다 6배 긴 video input
Method
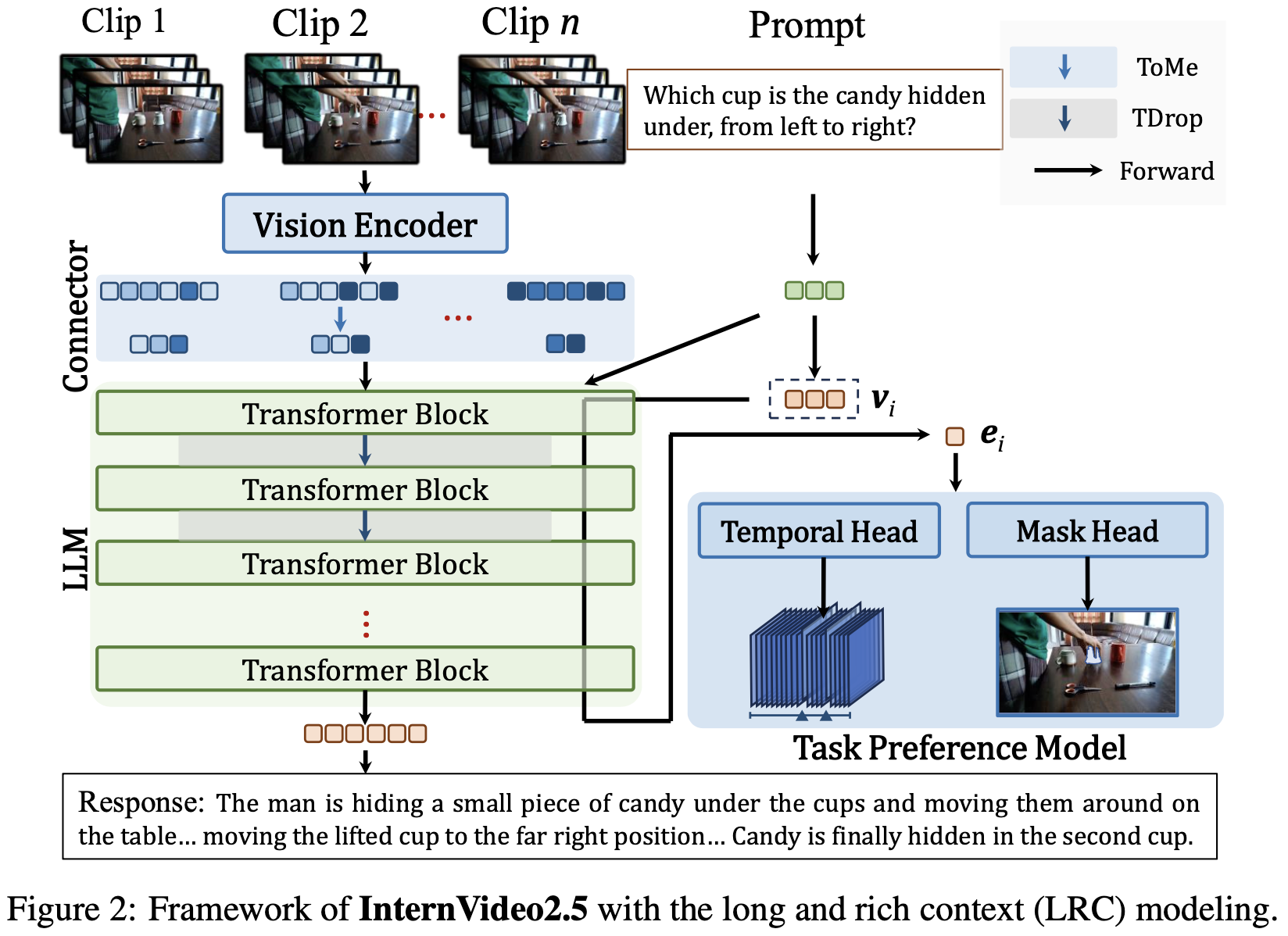
Video Length Adaptive Token Representation For Long Multimodal Context
length-adaptive token representation approach를 제안함.
- dynamic frame sampling
- Hierarchical token Compressions (HiCo)
- spatiotemporal-aware compression
- adaptive multimodal context consolidation
Adaptive Temporal Sampling
- 이름은 거창한데, short video는 15fps, long video는 1fps로 sampling한 것이다.
Hierarchical Token Compression
- video를 $T$개 temporal segment로 나누고
- 각 segment를 M개의 token으로 만든다.
- 이걸 다시 adaptive compression으로 N개로 줄인다. (N<M)
- 여러 pooling method 중 semantic similarity-based token merging (ToMe) 1이 가장 좋았음.
Multimodal Token Dropout
- two-phase token reduction함.
- uniform token pruning in early layers
- attention-guided token selection in deeper layers
- 각 token에 대해 token preservation probability를 정해두고 Bernoulli sampling해서 keep, discard를 결정한다.
- two-phase token reduction함.
→ Discussion 1 참조
Enhancing Visual Precision in Multimodal Context through Task Preference Optimization
- head를 달아서 여러 task를 통해 학습시킴.
- Visual Perception Perference: 2개로 구성됨
- Temporal Understanding
- visual seq와 text query를 받아 temporal boundaries와 relevance score를 측정
- 뭐한다는 건지 정확히 모르겠다.
- Instance Segmentation
- image encoder, mask decoder로 구성하여 segmentation model 학습
- Temporal Understanding
Training Video Corpus for Multimodal Context Modeling
- General하게 img-txt, vid-txt, txt, long-vid 데이터를 이용하여 train했다.
- Task Specific하게는 다음 task에 train했다:
- referring segmentation: MeViS, SAMv2
- SAMv2는 referring segmentation set이 아님
- 헷갈리게 써놨지만 SAM2를 mask decoder로 썼다는 뜻인듯
- Spatial Grounding: AS-V2, Visual Genome, RefCOCo, RefCOCOg, RefCOCO+
- Temporal Grounding: DiDeMo, QuerYD, HiRest, ActivityNet, TACoS, NLQ
- referring segmentation: MeViS, SAMv2
Progressive Multi-stage Training
- Foundation Learning
- Fine-grained Perception Training
- Integrated Accurate and Long-form Context Training
Discussion
- compressed video token을 random dropping하는거 흥미롭다.
- 일종의 VideoMAE처럼 masking & training으로 봐도 될 듯
- RVOS를 너무 못함.
Daniel et al. Token merging: Your vit but faster. arXiv, 2022. ↩︎