Motivation
- 당시 기존 모델들은 image domain이나 video domain 둘 중 하나만 받거나, 둘 다 받아도 한 쪽을 prioritize하는 경우가 많았음.
- Image priority: LLaVA, LLaVA-1.5, Flamingo
- Video priority: Video-ChatGPT
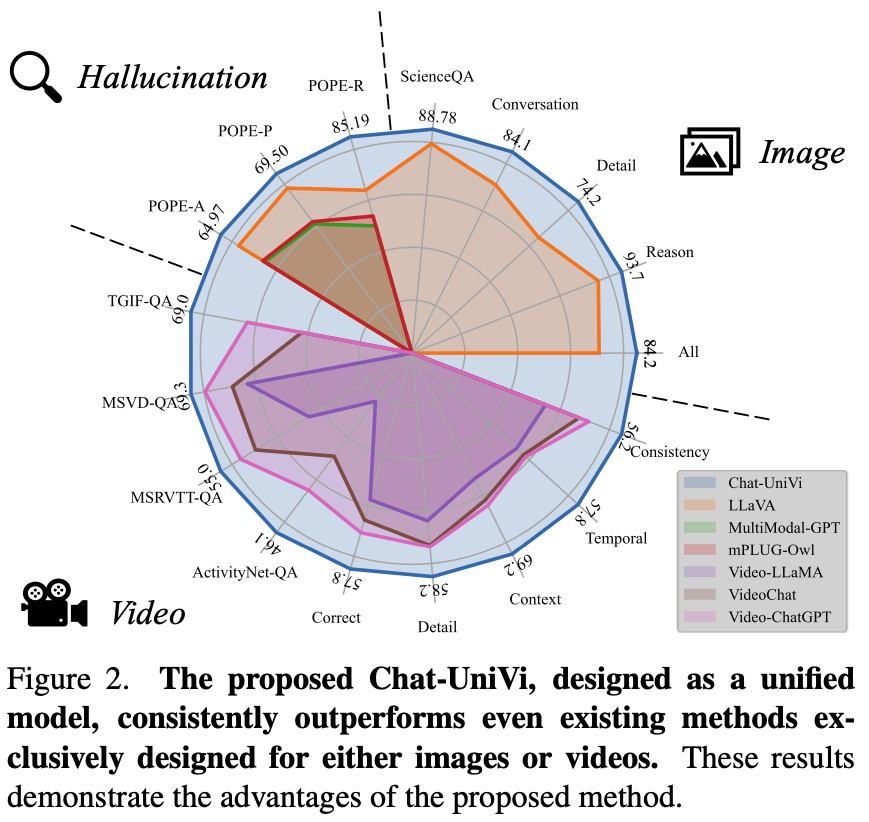
- Chat-UniVi, a Unified Vision-language model을 제안.
- dynamic visual token을 통해 image와 video를 둘 다 능숙하게 이해할 수 있음.
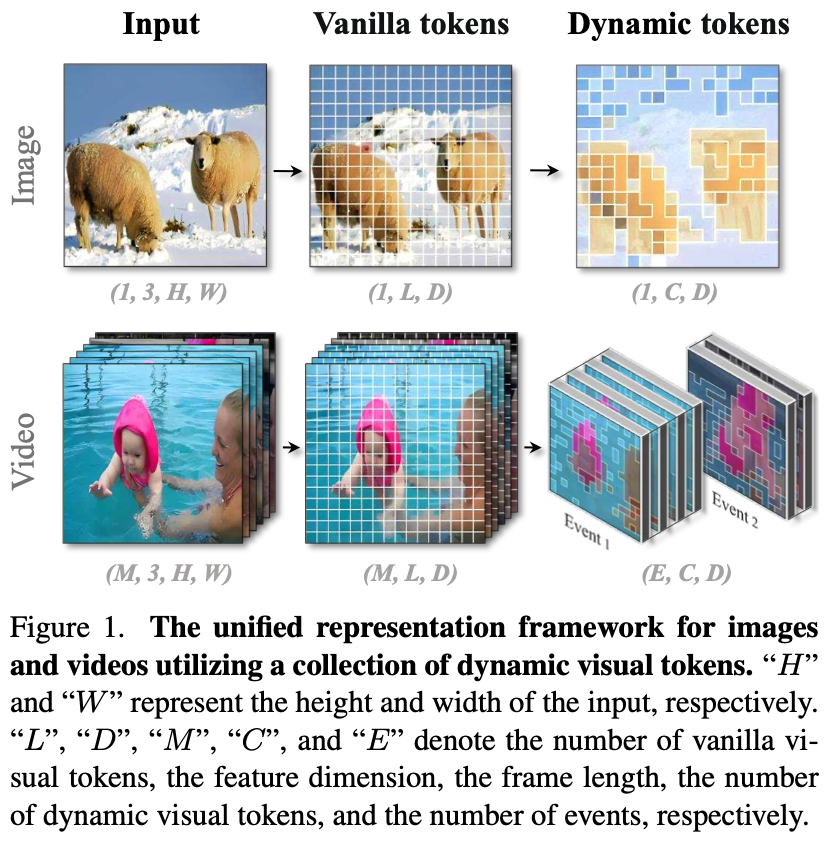
- Fig. 1의 image를 보면, 중심 object는 fine-grain하게 표현되지만 background는 하나의 token으로 표현됨.
- video의 경우, 먼저 여러 event로 나누어짐. 그 후, visual token은 여러 frame에 걸쳐 expand되어 dynamic을 포착함.
- long video의 경우 더 많은 token을 할애함.
- token merging
- progressive하게 similar semantic을 가진 token을 merge함.
- ViT로 encode된 token을 DPC-KNN으로 merge함.
- DPC-KNN은 k-NN based method임.
- Video의 경우 frame-level에서 DPC-KNN을 사용한 뒤 같은 cluster 내에서 token merging함.
- multi-scale representation을 제공함.
Methods
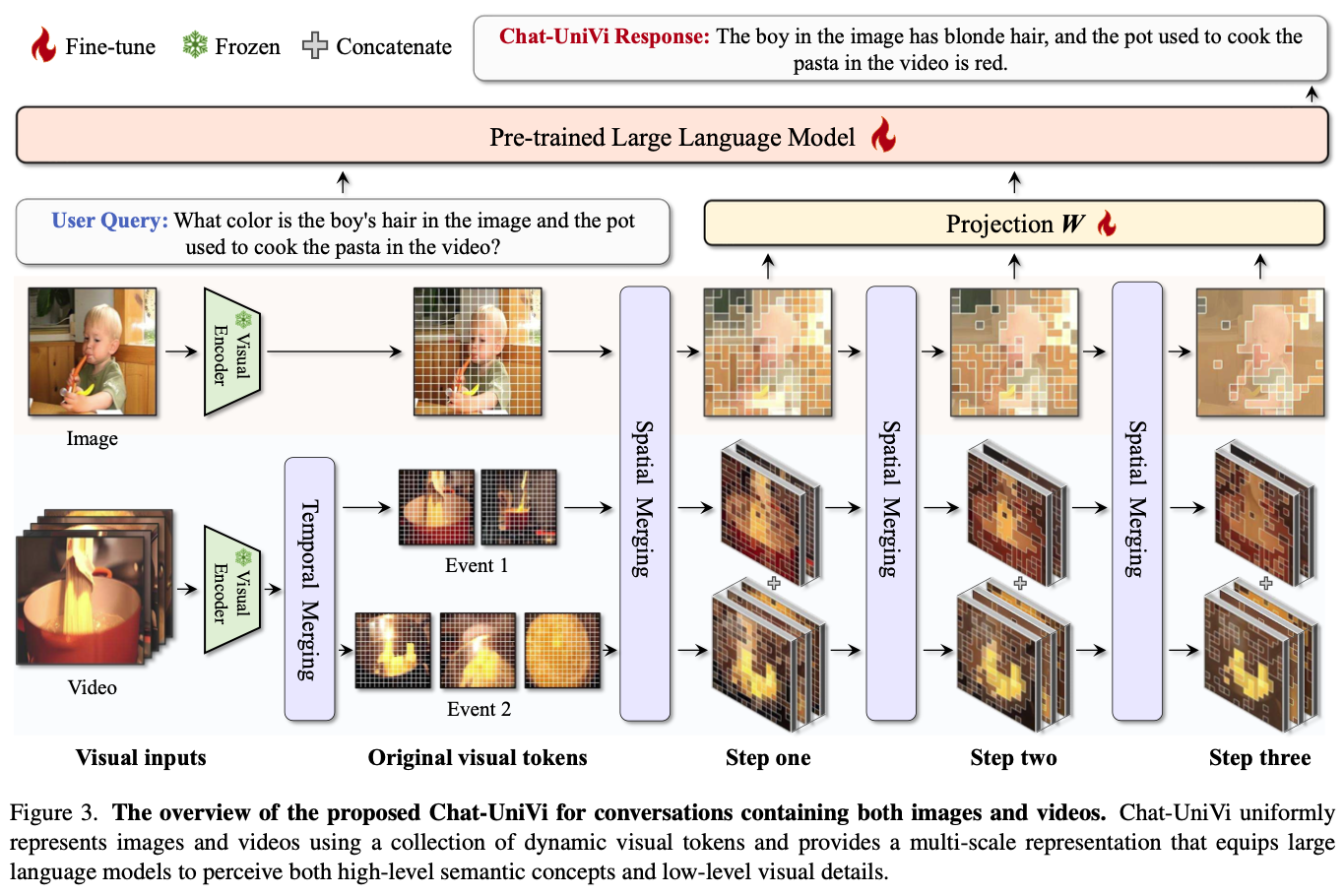
Dynamic Visual Tokens for Image and Video
Spatial Visual Token Merging
- CLIP으로 visual token $\mathbb{Z} = \{z_i\} ^L_{i=1}$ 를 얻음.
- DPC-KNN1으로 visual token을 cluster함.
- 이를 통해 다른 high density token과의 Euclidean distance를 구해서 cluster한다.
Temporal Visual Token Merging
- 단순한 temporal token merging은 temporal information의 loss를 초래할 수 있음.
- 따라서 video를 몇 개의 event로 나눈 뒤 해당 event 안에서만 temporal merging함.
- 한 frame의 모든 token을 mean-pooling해서 frame-level representation을 얻음.
- 이를 DPC-KNN1을 이용하여 clustering함.
- 얻은 cluster 내에서 spatial visual token merging과 같은 방법으로 token merging함.
- 얻은 visual token들은 event 순서대로 concatenate함.
Multi-scale Representation
- 여러 step으로 progressive하게 merging함으로써 hierarchical한 구조를 얻음.
- 세 단계로 aggregation을 진행하고 concatenate함.
- linear projection하여 language embedding token으로 transform함.
- 이를 통해 LLaVA의 256 token보다 더 적은 112 visual token만 사용함.
Multimodal Training Scheme
- 2단계로 training을 진행함2.
- stage 1: Multimodal Pre-training. LLM과 visual encoder를 freeze하고 projection matrix만 train함.
- stage 2: Joint Instruction Tuning. LLM과 proejction matrix를 finetuning함.
- single image, multiple image, video를 이용함.
- multi-turn, single-turn conversation으로 train함.
Experiments
Experimental Setup
- Model Settings
- CLIP vision encoder
- Vicuna-v1.5-7B
- Dataset
- image-caption datasets
- COCO
- CC3M-595K
- multimodal in-context instruction datasets
- MIMIC-IT
- visual instruction datasets
- LLaVA
- video instruction datasets
- Video-ChatGPT
- image-caption datasets
GPT-based Evaluation
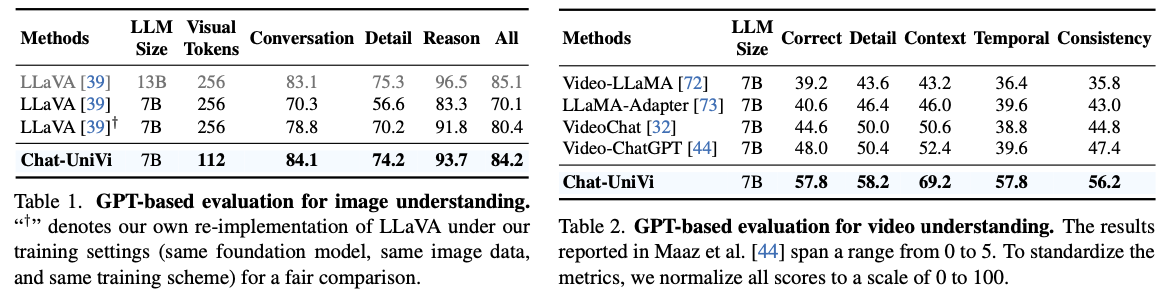
- evaluation result by GPT-4 in image understanding is reported in Tab. 1
- evaluation result by GPT-4 in video understanding is reported in Tab. 2
Question-Answer Evaluation
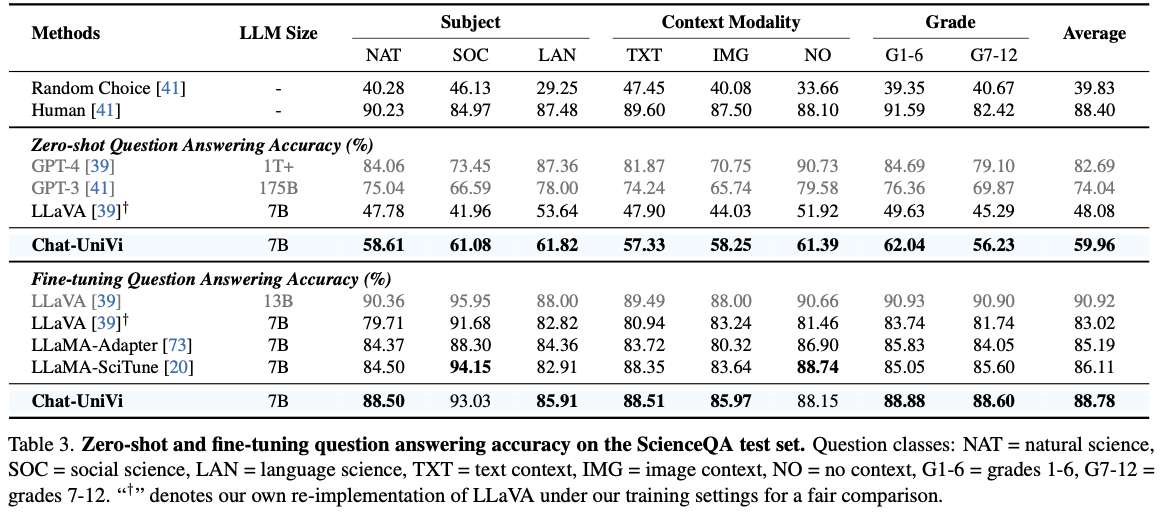
- ScienceQA performance is reported in Tab. 3.
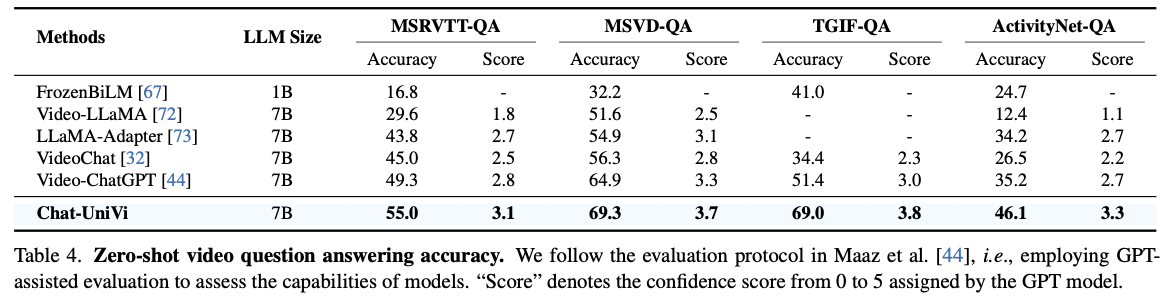
- Zero-shot VQA performance is reported in Tab. 4.
Object Hallucination Evaluation
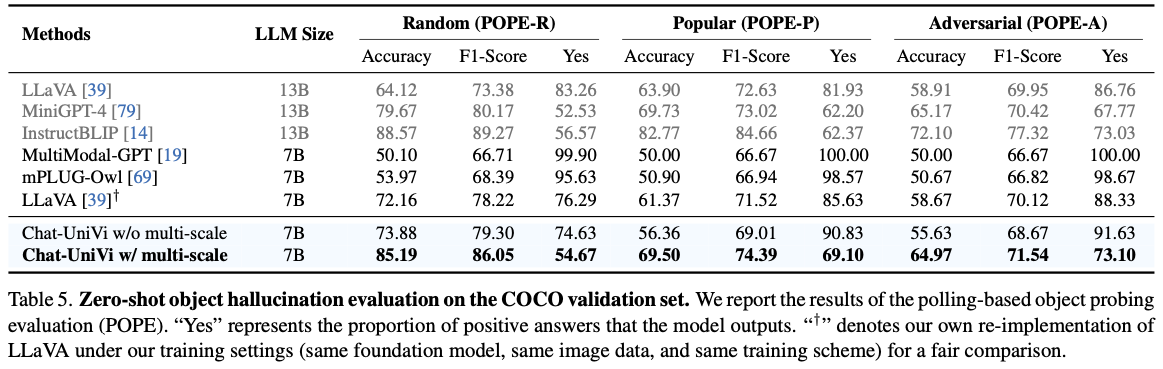
- Polling-based object probling evaluation (POPE) result is reported in Tab. 5.
Ablation Analysis
Effect of the Tuning Scheme
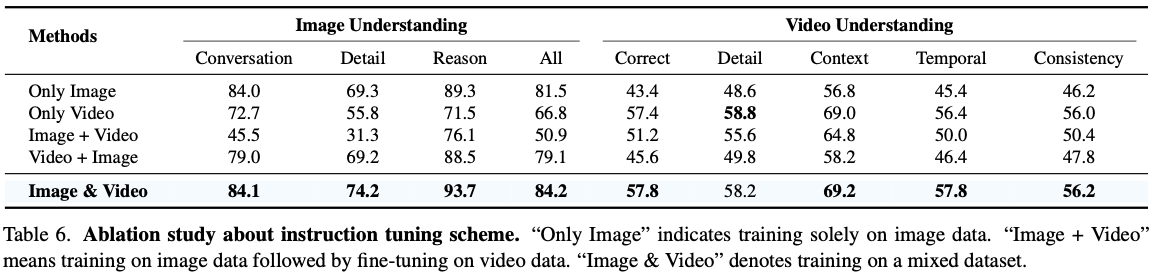
- Ablation study on the instruction tuning scheme is reported in Tab. 6.
- image domain에 pretraining하고 다른 domain에 finetuning하는 것은 performance degradation을 가져옴.
Effect of the Number of Spatial Visual Clusters
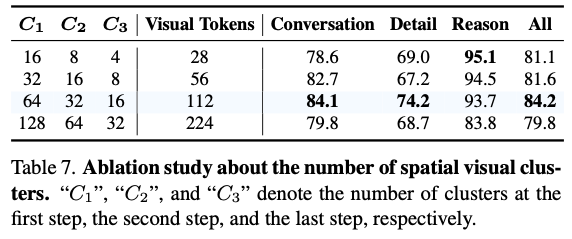
- visual token이 너무 많아도 성능이 하락함.
- paper에서는 redundancy로 인한 것으로 예측함.
- 비율의 차이에 대한 분석은 없는 점이 아쉬움.
Effect of the Number of Temporal Visual Clusters
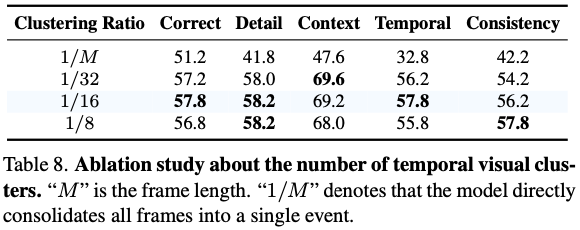
- temporal visual cluster의 개수가 너무 적으면 temporal information을 놓침.
- 반대로 너무 많을 경우 computational overhead가 커짐.
- 다만 이 수치는 input video 개수에 depend되는 heuristic한 값으로 생각됨. temporal clustering이라는 방법 자체가 어느 video에나 적용할 수 있는 방법이 아니므로 좋지 않은 방법으로 생각됨.
Qualitative Analysis
Human Evaluation
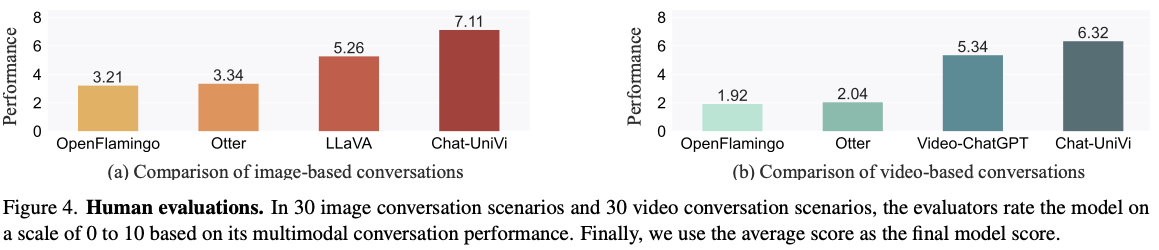
- human evaluation에서 좋은 평가를 받음.
Visualization of the Dynamic Visual Tokens

- spatiotemporal token merging을 visualize한 것임.
- 오른쪽 아래 event 3의 figure를 보면 background다 뭉뚱그려 묶이는 것을 볼 수 있음. salient object를 인식하는 데에 어려움이 있을 것으로 생각됨.
Discussion
Temporal Visual Token Merging의 event 단위로 문제를 쪼개는 것은 너무 semantics-centric한 방법이다. 여러 event에 걸쳐서 동일한 object가 끊임없이 나오는 경우에는 같은 object의 track을 얻을 수 없도록 하는 방법일 것이다.
event 간 선후 관계는 어떻게 encode되는지? 특별히 없는 것 같은데 temporal하게 이해하는 것이 critical한 MVbench같은 scenario에서도 잘 동작할 수 있을지 궁금함.
여전히 각 video는 224×224 resolution의 64 frame만 sampling됨. 충분하지 않는 경우가 있을 수 있다.