Papers
TAP-Vid (NeurIPS 2022 Datasets and Benchmarks Track)
TAP-Vid: A Benchmark for Tracking Any Point in a Video

tracking any point (TAP) problem을 정의함.
- $(x,y,t)$로 정의된 point를 frame별로 track한 결과 $(x_t, y_t)$를 predict
- 해당 point가 occluded인지 나타내는 binary indicator $o_t$를 predict

Video는 real-world video와 synthetic video로 구성
- real-world dataset은 human annotation
- synthetic dataset은 perfect groundtruth annotation

Metric
- Occlusion Accuracy (OA)
- simple classification accuracy for the point occlusion on each frame
- $<δ^x$
- point가 visible한 frame의 position accuracy
- gt의 threshold 내에 있는 point의 비율 측정1
- 256×256으로 resize된 image에서 1,2,4,8,16 의 5가지 threshold로 측정해서 $<δ^x_{avg}$ 측정
- Jaccard at $δ$
- $TP/TP+FP+FN$
- FP: occluded되어 있지 않다고 판단했으나 gt는 occluded거나 threshold 밖에 있는 prediction
- FN: occluded라고 판단했으나 gt는 visible하거나 threshold 밖에 있는 gt
- $< δ^x_{avg}$
- 위와 같은 threshold 기준
- $TP/TP+FP+FN$
- Occlusion Accuracy (OA)
Particle Video Revisited (ECCV 2022)
Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories
기존에 제시된 “particle video”2는 다음 특징을 지님.
- motion을 particle로 보고 trajectory를 확인
- 이 방식은 optical flow와 달리 occlusion scenario에서도 계속 track할 수 있음.
- 긴 temporal context를 반영할 수 있음.
Persistent Independent Particles (PIPs) 제안.
- $(x,y,t)$ frame을 받아서 $(x_t,y_y)$와 occlusion $v_t\in[0,1]$를 output으로 return
- 모든 particle을 indepedent하다고 가정함.
- temporal prior를 활용함.
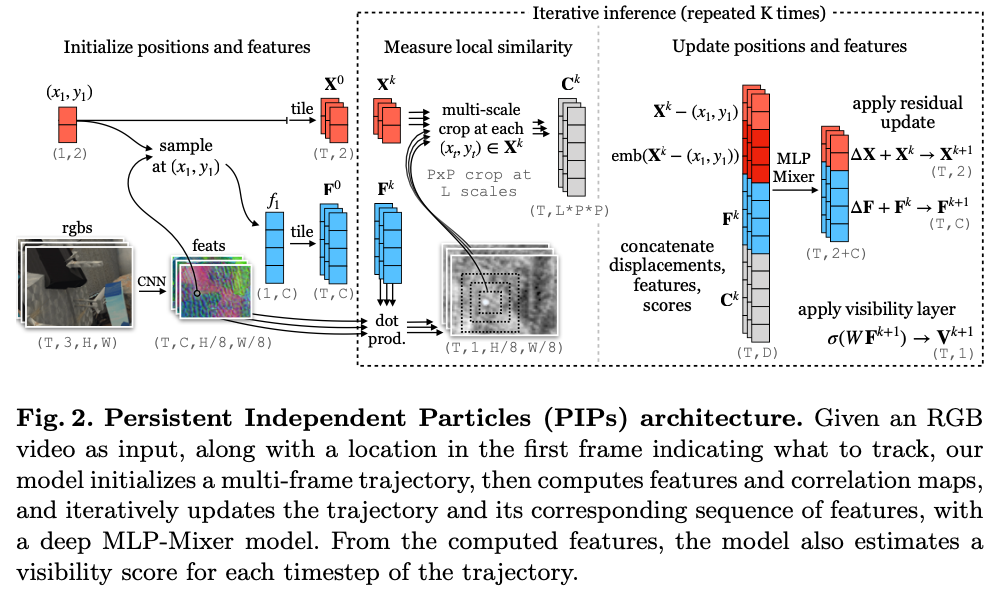
Method
- Extracting Features
- 2D convnet으로 feature extraction하고 1/8 resolution으로 downsampling
- Initializing Each Object
- first coordinate의 bilinear sampling으로 target의 feature vector를 feature map에서 가져옴
- $C$ dim feature를 원래 위치에서 frame 별로 sample하여 $F^0\in T×C$를 얻음
- 위치에 대해서도 sampling하여 $X^0 \in T×2$를 얻음.
- 이는 inference 과정에서 $X^k, F^k$로 update됨.
- Measuring Local Appearance Similarity
- feature가 가장 가까운 patch를 crop함.
- Iterative Updates
- MLP로 feature matrix, correlation matrix, position matrix를 이용하여 track함.
- Extracting Features
TAPIR (ICCV 2023)
TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
- query point에 대한 per-frame matching으로 coarse한 영역 탐색
- entire trajectory를 refine
- TAP-Net과 PIPs의 장점을 결합한 방법
OmniMotion (ICCV 2023 Best Student Paper)
Tracking Everything Everywhere All at Once
- globally consistent motion field로 video의 every pixel을 jointly track
- video를 quasi-3D canonical volume으로 만들고 bijective correspondence를 만듦
- video의 neural field를 optimize해서 long-range temporal consistency를 ensure
CoTracker (ECCV 2024 Oral)
CoTracker: It Is Better To Track Together
- point가 서로 independent하다는 가정을 제거하고 inter-depedency를 가정하여 dense point track
DINO-Tracker (ECCV 2024)
DINO-Tracker: Taming DINO for Self-Supervised Point Tracking in a Single Video
- pretrained DINO를 이용한 long-term dense tracking
- video가 들어오면 DINO를 test-time training
FlowTrack (CVPR 2024)
FlowTrack: Revisiting Optical Flow for Long-Range Dense Tracking
- per-frame optical flow prediction을 먼저 함.
- unreliable segment를 찾아서 error compensation module로 correct
- error compensation module은 spatiotemporal attention하는 Transformer
Dense Optical Tracking (CVPR 2024)
particle point tracking과 optical flow를 결합
- 적은 수의 long-range point track을 수행
- 만든 sparse trajectory를 dense optical flow의 guidance로 사용하여 dense motion field와 occlusion map을 만듦