The Devil is in Temporal Token: High Quality Video Reasoning Segmentation (CVPR 2025)
Motivation
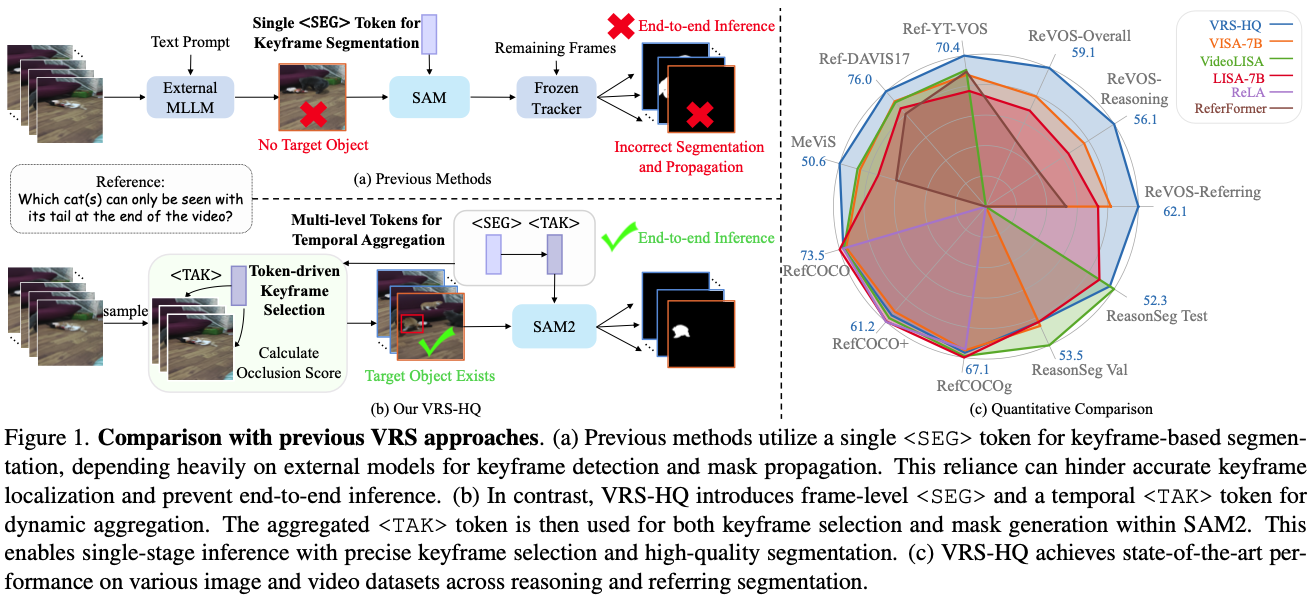
This paper starts with shortcomings of existing MLLM-based RVOS models, such as VISA and VideoLISA. Three limitations are listed:
- Limited Temporal Context: Exisiting methods rely on just one segmentation token, leading to insufficient temporal information.
- Suboptimal Keyframe Detection: In VISA, LLaMA-VID was used for keyframe detection which can produce inaccurate keyframes.
- Decoupled Segmentation and Propagation: In VISA, SAM and XMem were used, preventing end-to-end training and inference.
To address the problems above, this paper suggests three remedies:
- Larger number of tokens to efficiently encode temporal and spatial information, via heirarchical manner.
- Introducing occlusion scores to precisely choose the keyframe.
- End-to-end architecture by intergrating the MLLM with SAM-2.
→ I think the keyframe-based methods are suboptimal though
Method
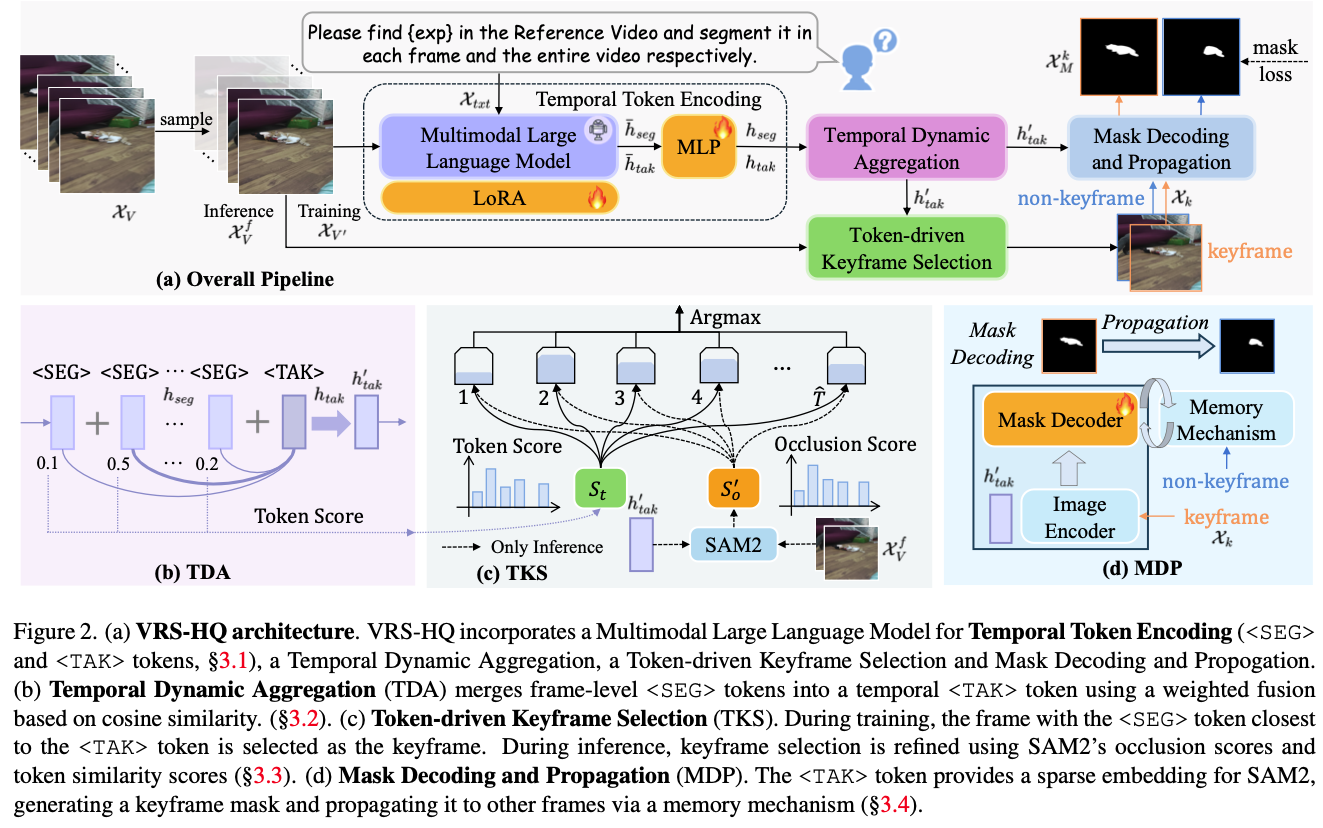
The method of VRS-HQ is composed of four parts – Temporal Token Encoding, Temporal Dynamic Aggregation, Token-driven Keyframe Selection, and Mask Decoding and Propagation.
Temporal Token Encoding
Two tokens are introduced in this paper– intra-frame token for spatial information and inter-frame token for temporal information.
<SEG> and <TAK> tokens augmented the vocab of the MLLM. When prompt and sampled video frames are input into the MLLM, it generates a response containing the two tokens through autoregressive manner.
Then, the final token embeddings <SEG> $\bar h_{seg} \in ℝ^{T'×d'}$ and <TAK> $\bar h_{tak}\in ℝ^{1×d'}$ are extracted and projected using MLP.
$$h_{seg}, h_{tak} = MLP(\bar h_{seg}), MLP(\bar h_{seg})$$Then they are fed into SAM-2.
Temporal Dynamic Aggregation
Temporal Dynamic Aggregation is a method to integrate positional and semantic information of the targets.
Keyframes as Token Similarity. <SEG> tokens는 전체 video에 대해서 존재하고, <TAK> token은 하나의 frame dimension으로 존재한다. 이때 특정 frame에서의 <SEG> token slice와 <TAK> token의 cosine similarity가 높으면 keyframe인 것으로 가정한다.
→ 이 가정이 valid한지 다시 생각해보기. TAK token은 하나만 나오는 것 같은데, 이건 하나의 frame을 가리키는 것인가? 뒤에 어떻게 사용되는지를 확인해 보면 될 듯
Similarity-based Weighted Fusion.
Fig. 2(b)를 참조하면 좋은데, global video context를 반영하기 위해서 cosine similarity를 이용해서 seg token 값을 attention하여 더한다:
$$h'_{tak} = h_{tak} + α \sum^{T'}_{i=1} λ_i h_{seg}[i]$$이때 α는 fusion coefficient이다.
Token-driven Keyframe Selection
LLaVA-VID에 의존하던 VISA의 문제를 해결하기 위해서, TKS를 제안한다. 특별히 다른 것은 없고, TAK embedding을 통해서 keyframe selection을 하는 expert module이다.
CLIP을 이용하여 expression $χ_{exp}$ 과 가장 align되는 frame $\hat T$ 개를 찾는다: $χ_V^f \in ℝ^{\hat T×3×H×W}$ 이를 mask decoder인 SAM-2에 넣어서 object occlusion score $S_o \in ℝ^{\hat T × 1}$ 를 얻는다:
$$ S_o = \mathcal{MD} ( \mathcal{E} (\mathcal{X}^f_V),h'_{tak})$$
Mask Decoding and Propagation
$$ \mathcal{X}^k_M = \mathcal{MD} ( \mathcal{E} (\mathcal{X}^k,h'_{tak}))$$위 수식으로 keyframe에 대한 mask를 만든다. 이를 bidirection하게 propagate해서 나머지 amsk를 만든다.
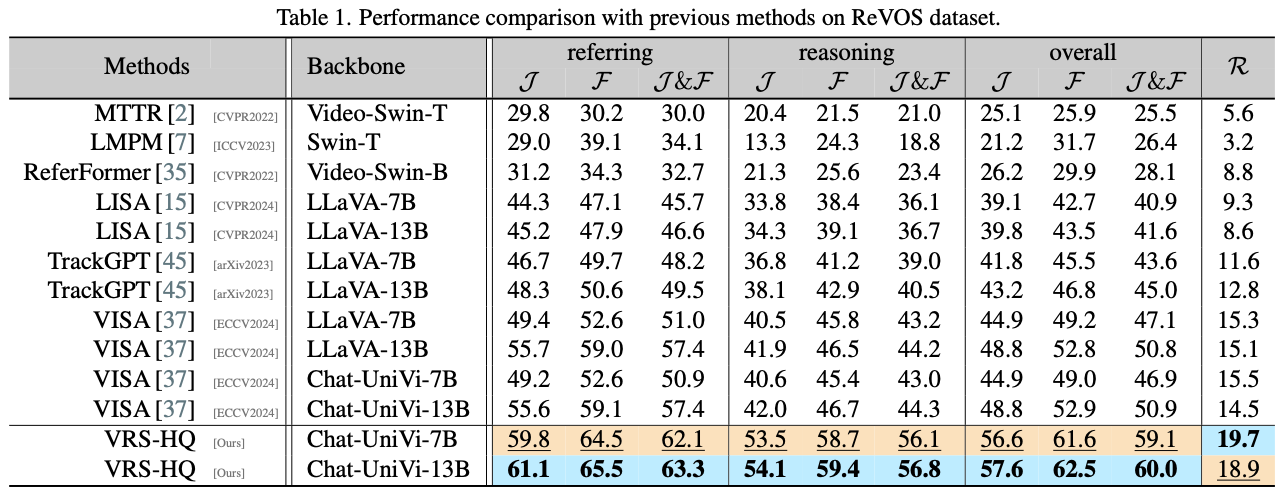
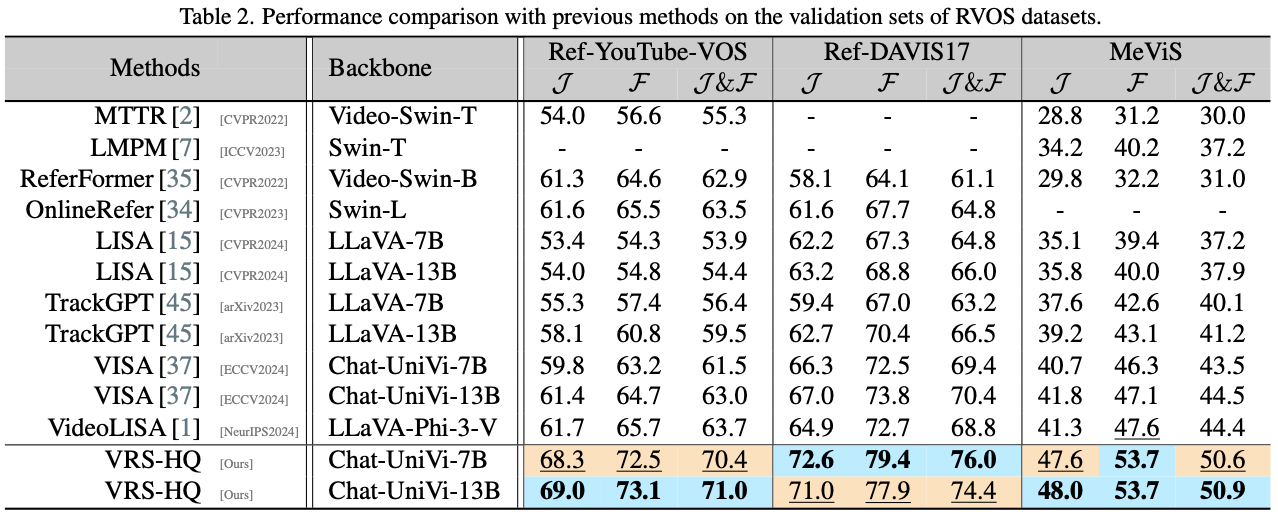
Experiments

Discussion
왜 keyframe selection에 매달리는건지? 그냥 token과 이전 frame으로 하면 된다. 없으면 없는 것
MLLM은 video를 어떻게 보는지? 그리고 그게 어떤 영향을 미치는지 -> Chat-UniVi를 따른다. 이거 paper 봐야할듯