CVPR 2025에 accepted된 paper 중, video segmentation과 관련된 paper들을 정리한다.
SAMWISE (CVPR 2025)
SAMWISE: Infusing wisdom in SAM2 for Text-Driven Video Segmentation
Abstract
- SAM2를 freeze하고 RVOS task에 적용하려는 시도.
- adapter를 사용하여 finetuning을 피함.
- video segmentation의 시간적 측면에 집중함.
- LLM은 사용하지 않음 → reasoning 불가.
Motivation
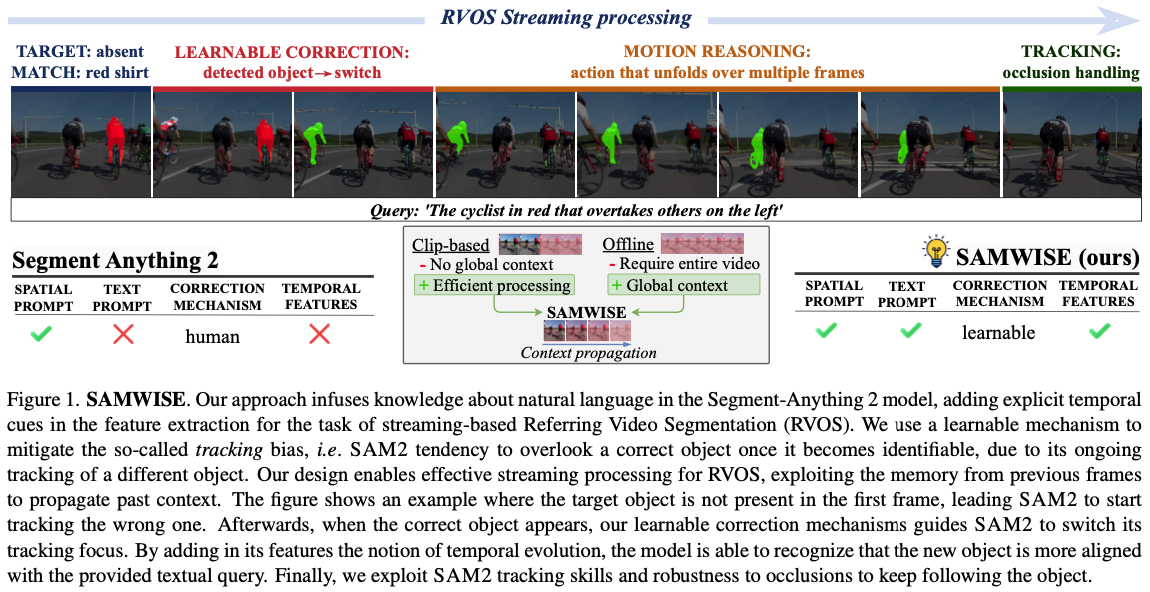
- RVOS task에서, image-level로 divide-and-conquer하는 paradigm은 MeViS와 같이 global context를 이해해야 하는 video에서 fail함.
- 따라서 최근 model들은 trajectory를 먼저 만든 후 선택하는데1, 이는 streaming이나 real-time으로 사용할 수 없음.
- SAM2는 memory-based mechanism으로 streaming할 수 있으므로 이를 이용하면 됨.
- SAM2를 이용하는 것의 challenge는 다음과 같음:
- Text understanding: SAM2는 spatial prompt로만 동작함.
- Temporal modeling: 먼저 recognize되고 track되어야 함. 그러나 SAM2는 temporal reasoning할 수 없음.
- Tracking bias: occlusion 등으로 종종 target object가 첫 frame에 absense한 경우, 잘못된 object를 track함.
Method
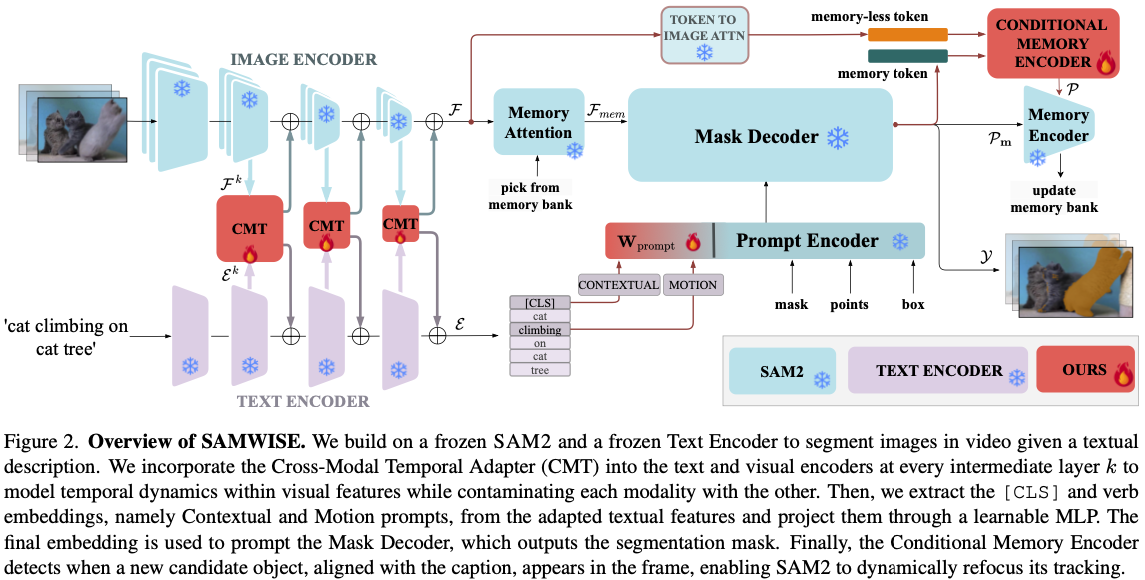
Prompting SAM-2
- SAM2 encoder에 넣기 위해 Contextual Prompt $\mathcal{E}_C \in ℝ^{1×C_t}$를 사용함.
- text query에 대한 information을 encode함.
- text feature의 [CLS] embedding을 사용함.
- Motion Prompt $\mathcal{E}_M \in ℝ^{1×C_t}$도 사용함.
- 이는 verb embedding에서 추출함.
- 두 prompt는 concatenate되고 3-layer MLP로 project됨. $$\rho=W_{prompt}(CAT[E_C,E_M])$$
- 이를 통해 context 정보와 motion 정보를 모두 포함할 수 있음.
Cross-Modal Temporal Adapter
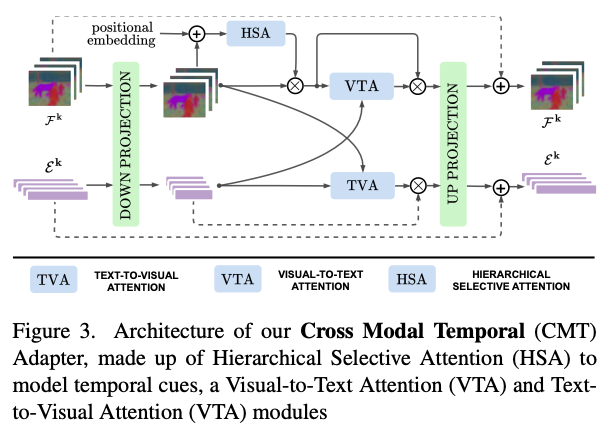
- Cross-Modal Temporal Adapter (CMT)는 이 방법의 핵심인데, image encoder와 text encoder가 finetuning 없이 서로를 aware하도록 만드는 역할임 (Fig. 2 참조).
- 기본적으로는 upsampler와 downsampler로 구성된 adapter와 residual connection으로 구성됨: $$Adapter(x) = x + σ(xW_{down})W_{up}$$
- visual feature $F$와 textual feature $E$에 대해서 다음과 같이 계산됨: $$ Adapter(F^k) = F^k + h (F^k W_{down,v},E^kW_{down,t})W_{up,v}$$ $$ Adapter(E^k) = E^k + h (E^k W_{down,t},F^kW_{down,v})W_{up,t}$$
- 자세한 구조는 Fig. 3에 표현됨.
Temporal Adaptation.
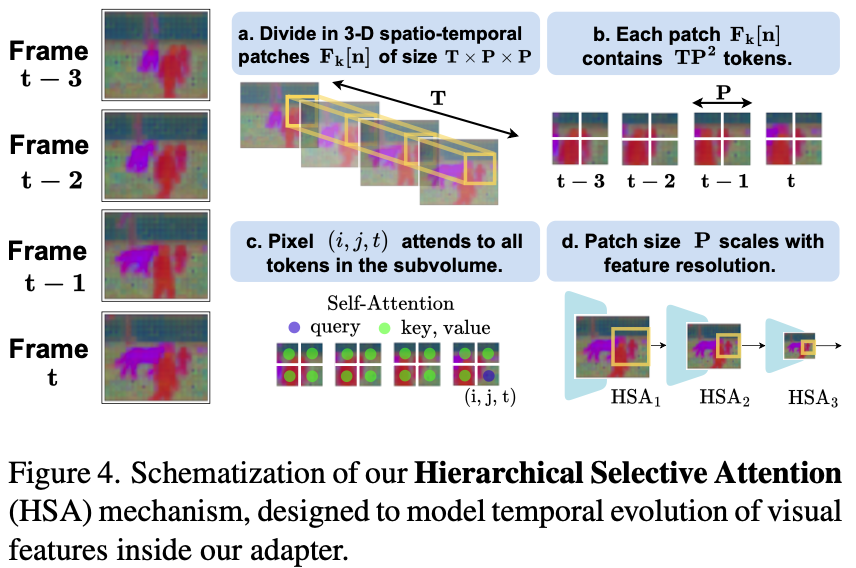
- 전체 clip에 대해서 self-attention하는 것은 비싸고 쓸모없음.
- object motion은 특정 region의 adjacent frame에서 span됨2.
- 따라서 Hierarchical Selective Attention (HSA)로 spatiotemporally proximal region에 대해서만 interaction을 확인함. → 아쉬운 측면이 있는 방법임. Discussion point 2 참조.
- 구체적으로는 다음과 같이 진행됨:
- video를 spatiotemporal하게 나누어서 $N$개의 subvolume으로 나눔.
- subvolume은 spatial하게 나누어져있고, temporal하게는 $T$만큼 span함. 직관적으로는, 공간적으로 작고 시간적으로 길쭉한 cube임 (Fig. 4 (a) 참조).
- 이 subvolume 안에서 self-attention함.
- 뒤쪽 HSA일수록 scale이 작음 (Fig. 4 (d) 참조).
- video를 spatiotemporal하게 나누어서 $N$개의 subvolume으로 나눔.
Cross Modal Adaptation.
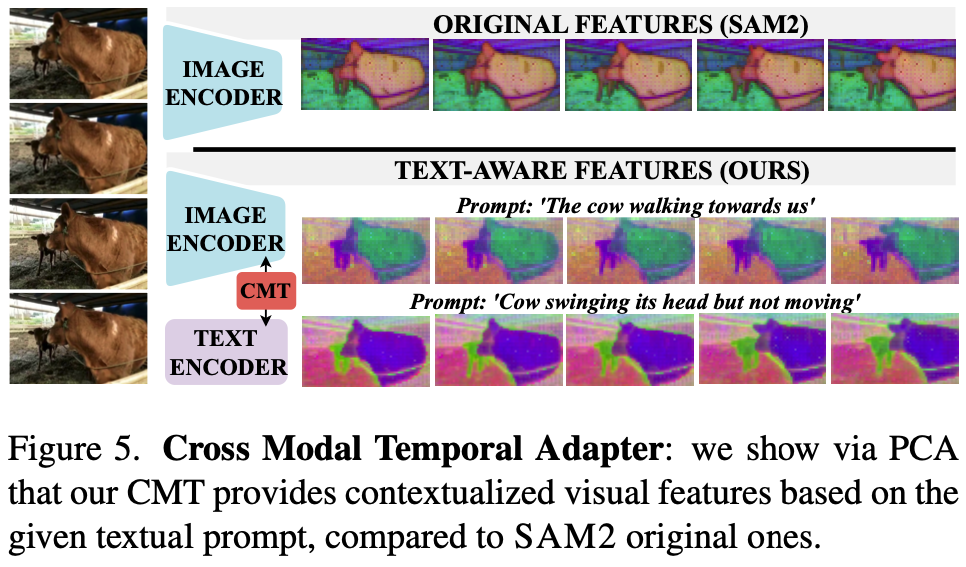
- HSA로 enrich된 feature에 cross-modality를 넣는 부분임.
- symmetric하게 Visual-to-Text Attention (VTA)와 Text-to-Visual Attention (TVA)가 있음.
- 각 frame의 visual feature $F^k[t]$에 대해서 temporal-independent하게 textual feature $E^k$와 cross-attention함. $$F^k[t] = F^k[t] * CA(F^k[t], E^k)$$
- text에 대해서도 이를 수행함.
- visual context와 align되도록 하는 것으로 해석할 수 있음. $$E^k = E^k * CA(E^k, F^K_{avg})$$
Mask Prediction
- mask decoder는 SAM2에서 freeze한 상태로 사용함.
- input은 prompt와 memory임.
- prompt의 생성 방식은 이전에 언급함.
- Memory Encoder가 memory bank module을 update함.
- Mask Decoder에는 mask token $τ_m$과 binary mask $M$을 리턴함.
Conditional Memory Encoder
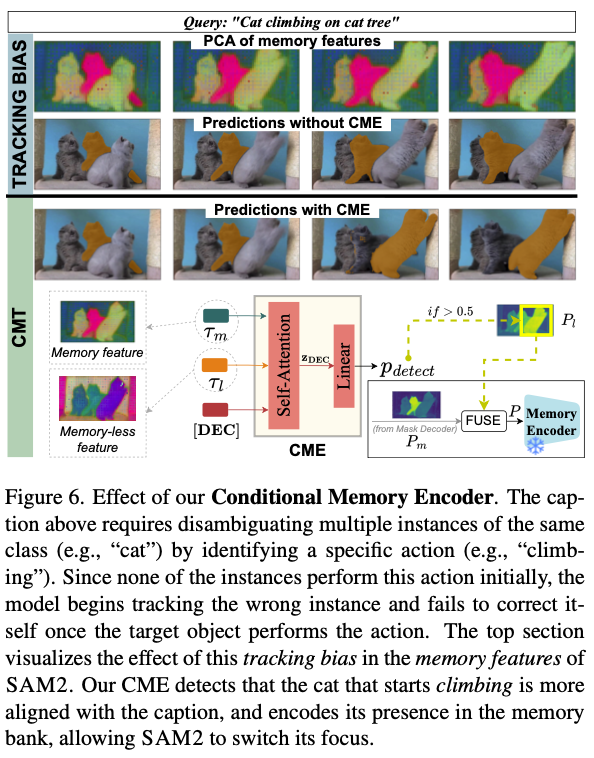
- SAM2의 tracking bias는 video에서 object가 존재하지 않는 경우에도 tracking하는 문제가 있음.
- 이 bias는 memory feature에 encode되어 있음.
- memoryless feature는 unbiased임.
- visual feature와 prompt를 이용하여 memoryless token $τ_l$을 얻음.
- Conditional Memory Encoder (CME)를 도입함.
- 새로운 object가 detect되면, frame에 대해 reprompt해서 preidction을 바꾸도록 함.
- 이렇게만 할 경우 false positive가 많아서 두 object를 모두 memory object에 넣음(soft assignement). → 이상한 방법임. discussion point 3 참조
Experiments
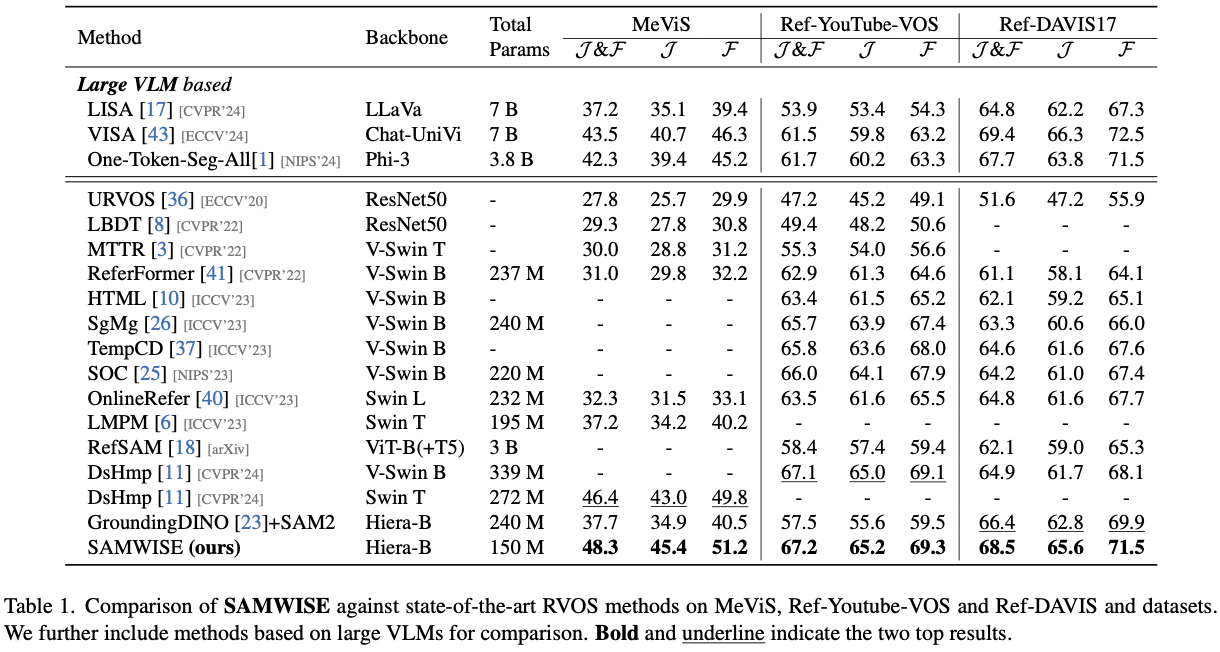
Discussions
- point 1. text feature보다는 visual feature를 건드리는 게 핵심으로 보임.
- language space와 align되어 있지 않은 ViT-based architecture를 쓰는 SAM2에게 text understanding은 어려운 문제임.
- visual encoder를 text align된 CLIP-based로 바꾸는 것은 현실적으로 불가능함.
- 따라서 지금까지는 text를 이해하는 encoder가 좋은 prompt를 제공하는 것으로 해결하였음.
- 이 paper의 핵심은 adapter를 통해서 SAM2의 visual feature를 language space와 align되도록 바꾼다는 점임.
- 다만 visual encoder와 cross-attention하는 text encoder라는 측면에서는 특별히 새로울 것은 없음.
- point 2. spatiotemporally proximal한 region에서만 interaction을 modeling하는 방법은 optimal하지 않아 보임.
- disappearance-reappearance scenario에서는 temporal하게 멀리 떨어진 frame에서, 다른 위치에서 같은 object가 등장할 수 있음.
- 이런 inductive bias를 explicit하게 추가하는 것은 heuristic함. wild한 문제를 푸는데 도움이 되지 않을 것임.
- point 3. CME는 이상함.
- SAM2가 tracking에 실패하도록 유도하는 방법임.
- video object segmentation에서 tracking 대상이 계속 바뀌어야 하는 상황은 없음.
- object presence하지 않은 경우에 다른 object를 masking하는 경우에는, 그 object를 masking하지 않도록 하는 것이 올바른 방법이라고 생각함.
- 여기서는 object absence인 경우에는 아무 object나 tracking하도록 방치하고, target object가 등장했는지만 체크함.
- 이는 J&F index가 false positive를 측정하지 못한다는 데에서 기인하는 문제임.
- CME는 J&F index를 fool하고 있음.
- SAM2가 tracking에 실패하도록 유도하는 방법임.
VideoGLaMM [RVOS]
VideoGLaMM : A Large Multimodal Model for Pixel-Level Visual Grounding in Videos
Abstract
- Grounded Conversation Generation, Visual Grounding, RVOS
- LLM, dual vision encoder, ST decoder로 구성된 architecture
- V → L, L → V adaptor로 VL alignment
- visually grounded conversation dataset 제작
- 38k VQA triplets
- 83k objects and 671k masks

Method
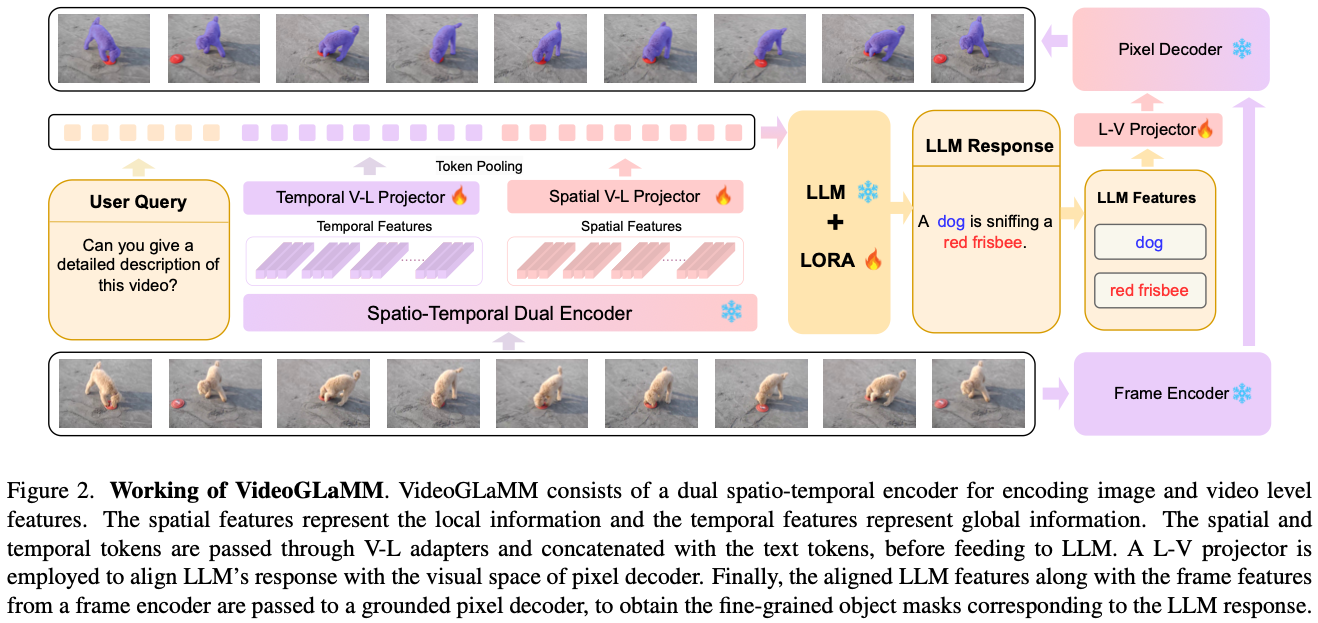
Architecture
Spatio-Temporal Dual Encoder
- spatial feature를 위해 각 frame을 independent하게 encoding한다.
- $$f_g = \mathcal{F}_g (V), V\in ℝ^{T×H×W×C}$$
- temporal feature를 위해 segment-wise Sampling3으로 time segment로 나누어 encode한다.
- temporal segment를 나누어 쓰는 방법인 것 같다.
- 해당 segment를 함께 encode하여 segment-wise global feature를 만든다.
- $$f_h = \mathcal{F}_h(V_k), V_k \in ℝ^{s×H×W×C}$$
- Dual Alignment (V→L) Adapters
- 두 feature는 따로 project되어서 LLM align된다.
- $$Z_g = \mathcal{W}_g(f_g)\ and \ Z_h = \mathcal{W}_h(f_h)$$
Large Language Model
- text와 spatiotemporal visual feature는 concat되어서 LLM에 feed된다.
- LLM에 <SEG> token이 vocab에 추가된다.
- $$E = LLM(\mathcal{Z}) = LLM([Z_g, Z_h, Z_{text}])$$
Pixel Decoder
- frame encoder와 pixel decoder는 SAM2를 갖다 쓴다.
- LLM의 SEG token last layer embedding으로 prompt embedding을 만든다.
- spatiotemporal cue를 쓰게 된다는 의도
- $$M = D(P(V),H(e^P_{seg}))$$ → 수식이 복잡해보이는데, 그냥 SAM2 encoder P랑 prompt encoder H를 쓴다는 뜻이다. P에는 video V가 들어가고, H에는 last layer SEG embedding이 들어간다.
Training Strategy
- end-to-end, single stage Training
- Specification
- image encoder: CLIP ViT-L/14
- temporal encoder: InternVideo2
- V→L projector: MLP from VideoGPT+[^6]
- LLM: Phi3-Mini-3.8B
- frame encoder, pixel decoder: SAM2
- GPU: 4 A100 40GBs
- L→V projector: scratch인듯
- encoder는 다 freeze, two adapters와 LoRA만 tuning
Benchmark

- semi-automatic annotation pipeline
- 3 stream으로 구성 → 디테일은 해당 paper 참조
Videos with only Mask annotations
- Fig. 3(a)
- Object Description Generation
- object들에 대한 bounding box를 먼저 만들고 이걸 crop해서 Gemini-Pro가 각 object의 rough caption 만들도록 함.
- Object Description Refinement
- video frame위에 bbox 그려서 Gemini-Pro가 detail description 만들도록 함.
- Caption Generation
-> 왜 이렇게 stage를 많이 만든건지?
Experiments

- task는 GCG (Gorunded Conversation), VG (Visual Grounding), RVOS이다.
- 숫자는 paper 참조
Discussion
- 확실히 video expert encoder를 갖다가 쓰고, 이상한 keyframe detection 같은거 안써서 방법이 훨씬 decent하긴 하다.
- GCG는 잘 모르는데, MeViS를 더 잘하는건 temporal하게 인식하는거 자체가 의미가 있다는 뜻인듯
- 여기서는 그냥 mask로 대답하라고만 했는데, output에서 뭔가 input text를 활용하는 방안이 없는지 궁금함.
- 예를 들어서 input text를 reconstruction하거나 다른 방식으로 이해했는지 확인할 수 있도록 guidance를 주면 더 잘할 수 있을지?
- STVG 등과 섞어서 train하는게 VOS에 도움이 된 것인지
References and Footnotes
He, Shuting, and Henghui Ding. “Decoupling static and hierarchical motion perception for referring video segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. ↩︎
Mandela Patrick, Dylan Campbell, Yuki Asano, Ishan Misra, Florian Metze, Christoph Feichtenhofer, Andrea Vedaldi, and Joao F Henriques. Keeping your eye on the ball: Trajectory attention in video transformers. Advances in neural information processing systems, 34:12493–12506, 2021. ↩︎
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Videogpt+: Integrating image and video encoders for enhanced video understanding. arXiv preprint arXiv:2406.09418, 2024. ↩︎