Introduction
Papers & Datasets related to the video object segmentation in complex scenes
OVIS (IJCV 2022)
Occluded Video Instance Segmentation: A Benchmark
MOSE (ICCV 2023)
MOSE: A New Dataset for Video Object Segmentation in Complex Scenes
 Figure 1: Examples of video clips from the coMplex video Object SEgmentation (MOSE) dataset.
Figure 1: Examples of video clips from the coMplex video Object SEgmentation (MOSE) dataset.
Motivation
Although current VOS models achieve almost perfect performance for each dataset, the target objects in the datasets still remain salient, dominant, and isolated. Therefore, the results cannot be used in realistic scenarios. This paper introduces a new large-scale segmentation benchmark, MOSE. As shown in Fig. 1, objects in MOSE are normally positioned in crowded and occluded scenarios.
MOSE Dataset
Specification:
- semi-supervised, interactive VOS
- contains high occluded scenarios
- resolution: 1920×1080
- # videos: 2,149
- # masks: 431,725
- # objects: 5,200
- # obj. categories: 36
- # video duration: 5-60s
Video Colellection and Annotation
The videos of MOSE are composed of two main parts—videos from OVIS and newly captured videos for real-world scenarios. When they adopt videos from OVIS, they selected videos where objects are do not fully shown in the whole frame. Object categories that are used to annotate the video are displayed on Tab. 1.
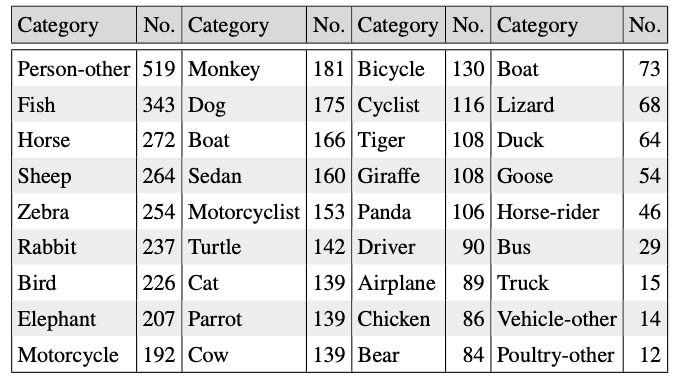 Table 1: A complete list of object categories and their #instances in the MOSE dataset.
Table 1: A complete list of object categories and their #instances in the MOSE dataset.
The following is the rules when they collect videos for the dataset:
- Each video must contain severe occlusions, otherwise, the video is discarded.
- The target object must shows either sufficient motions, variety of scales, or crowded with same objects.
The video resolution is 1920×1080 and the video length span to 5 to 60 seconds.
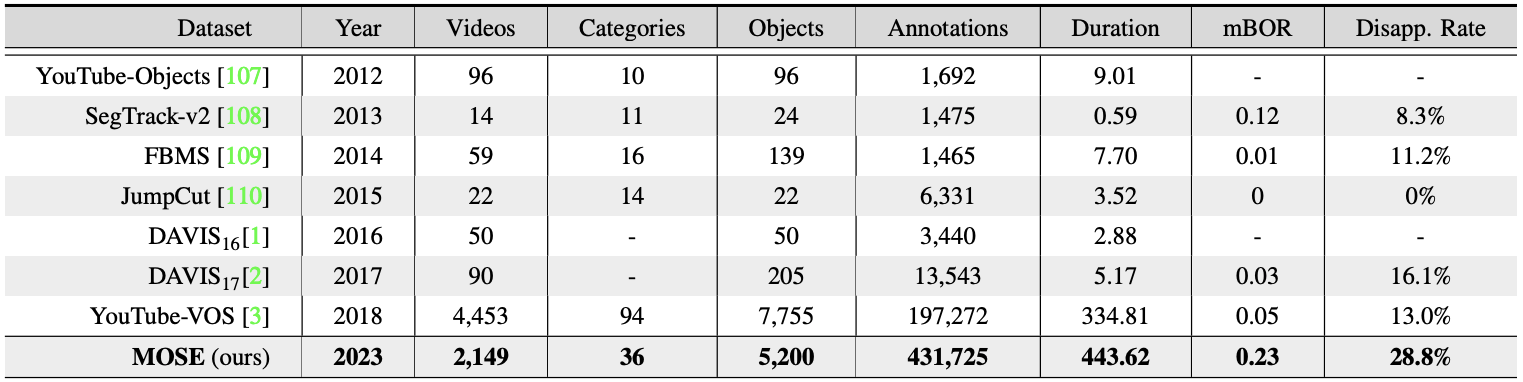 Table 2: Scale comparison between MOSE and existing VOS datasets.
Table 2: Scale comparison between MOSE and existing VOS datasets.
Dataset Statistics
The data analytics are shown in the Tab. 2.
Disappearance and Occlusion Analysis Previous OVIS defines a Bounding-box Occlusion Rate (BOR) to calculate the occlusion rate. However, as displayed in Fig. 2, BOR does not always align to the real occlusion.
 Figure 2: Failure cases of the BOR indicator
Figure 2: Failure cases of the BOR indicator
So, they calculated the number of disappeared objects that disappear in at least one frame of the video, followed by the disappearance rate that reflects the frequency of disappearance.
iDeA; I don’t think it is a proper metric… to calculate accurately, we have to count the rate of frames out of the total frames where the target object is fully occlueded. Or maybe we can further reflect the occlusion rate of the whole shape of the target object.
Experiments
Experiments are conducted to test the performance of existing methods on VOS datasets. One thing to note is that they re-implemented all the methods and trained again after replacing the YouTube-VOS dataset with the MOSE dataset and followed exactly the same scheme as the original one. I’ll omit the details, so if you are interested, please refer to the paper.
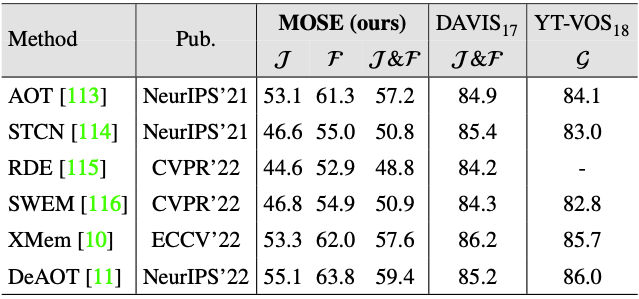 Table 3: Comparisons of SOTA semi-supervised methods on the validation set
Table 3: Comparisons of SOTA semi-supervised methods on the validation set
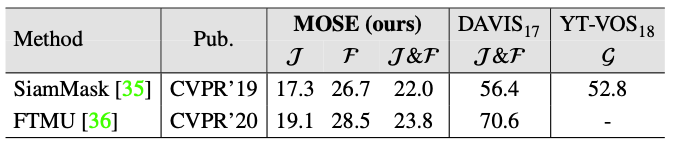 Comparisons of SOTA box-initialization semi-supervised methods on the validation set.
Comparisons of SOTA box-initialization semi-supervised methods on the validation set.
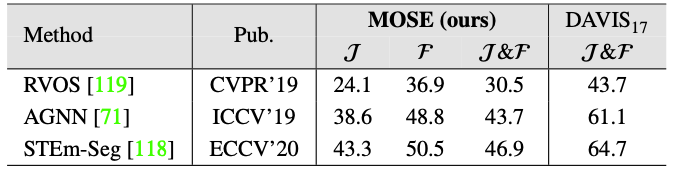 Comparisons of SOTA multi-object zero-shot VOS methods on the validation set.
Comparisons of SOTA multi-object zero-shot VOS methods on the validation set.
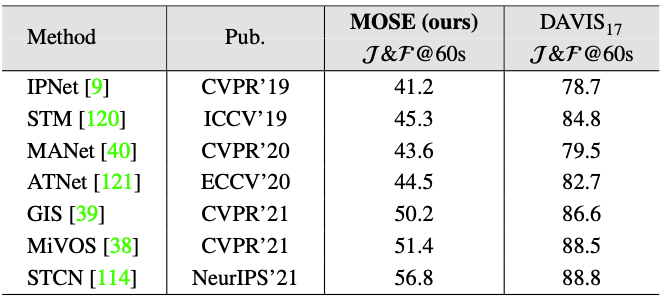 Comparisons of SOTA interactive VOS methods on the validation set. $\mathcal{J&F}$@60s denotes the $\mathcal{J&F}$ performance reached by methods within 60 seconds interactions.
Comparisons of SOTA interactive VOS methods on the validation set. $\mathcal{J&F}$@60s denotes the $\mathcal{J&F}$ performance reached by methods within 60 seconds interactions.
Discussions
Further Studies Presented on the Paper
Stronger Association to Track Reappearing Objects. It is necessary to develop a new method that can capture object after disappear-reappear. It is worth to note that, when an object reappear after disappear, normally the appearance is changed.
Video Object Segmentation of Occluded Objects.
Attention on Small & Inconspicuous Objects.
Tracking Objects in Crowd
Long-Term Video Segmentation
LVOS (ICCV 2023(v1), arXiv 2024(v2))
LVOS: A Benchmark for Large-scale Long-term Video Object Segmentation
Note: There are two versions of the LVOS dataset. The paper dealing with the first one has been accepted to ICCV 2023, and the second one can be found in arXiv. Both can be found on the above project page.
Note: This post is about the second version of the LVOS dataset.
Motivation
Existing video object segmentation task datasets only span around 5 seconds, with consistently visible target objects. Therefore, to reflect the real-world scenarios to the video object segmentation task, they propose the first large-scale long-term video object segmentation benchmark dataset, named Long-term Video Object Segmentation (LVOS).
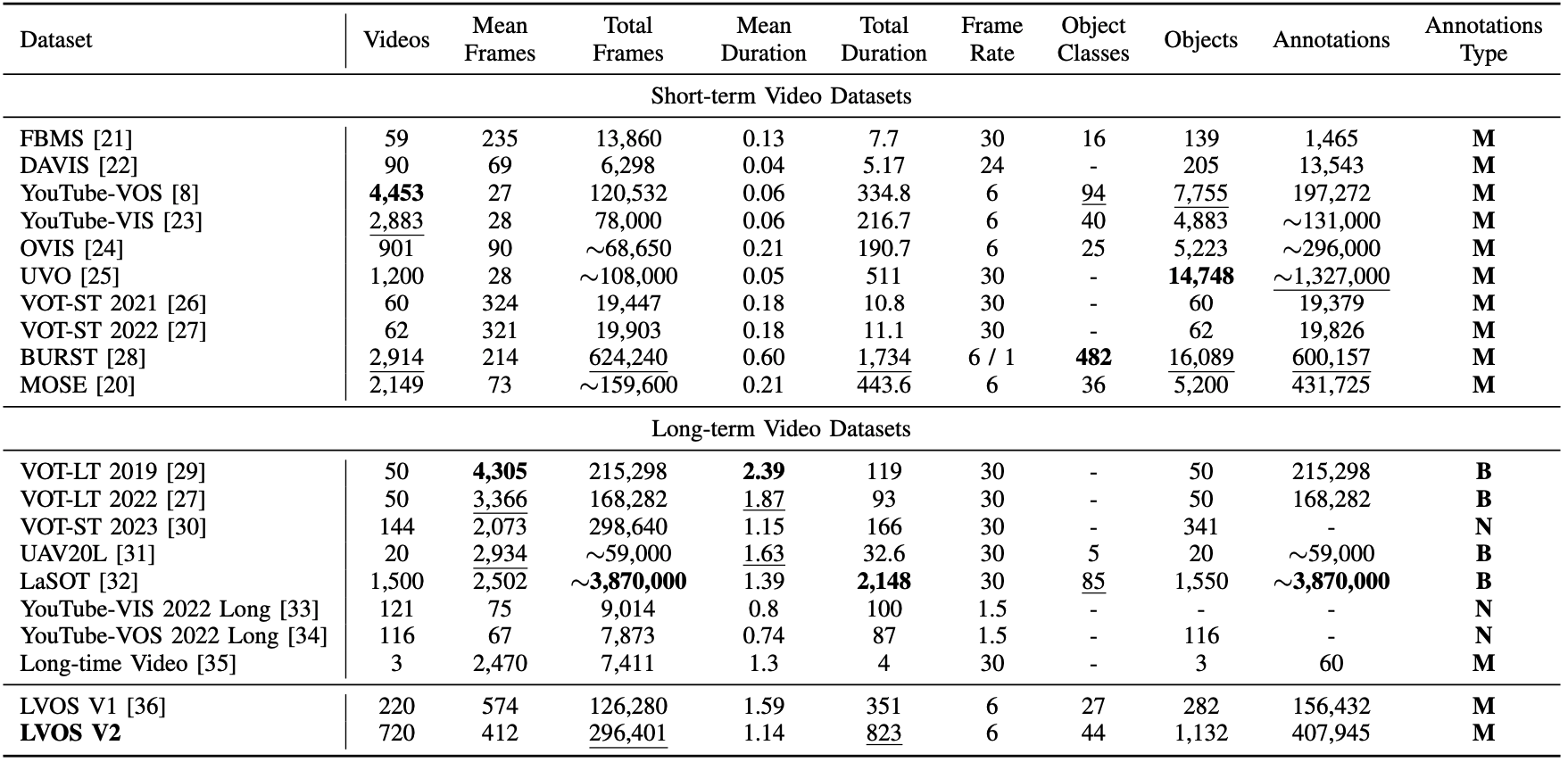
Specification:
- semi-supervised, unsupervised, interactive VOS
- resolution: 720P, but varies
- # videos: 720
- # frames: 296,401
- # masks: 307,945
- # objects: 1,132
- # obj. categories: 44
- # video duration: avg. 1.14 min (refer Tab. 1 for statistic detail)
 Figure 1: Example sequences of the Large-scale Video Object Segmentation (LVOS).
Figure 1: Example sequences of the Large-scale Video Object Segmentation (LVOS).
The major features of this datasets are long-term, large-scale, dense annotations, and comprehensive labeling. Additionally, they performed a series of experiments to evaluate 20 exisitng VOS models on LVOS under 4 different settings.
LOVS Dataset
Dataset Construction
Dataset Design. To generate the LVOS dataset, they adhered four principles following:
- Long-term: LVOS ensures a considerably long duration.
- Large-scale: They collected 297K frames across 720 videos.
- Dense and high-quality annotations: Each videos are annotated at a frame rate of 6 FPS.
- Comprehensive labeling: 44 categories are included in total, with 12 unseen categories from the COCO dataset.
Videos are collected from various sources. For details, please refer the original paper.
Semi-Automatic Annotation Pipeline
To avoid manual annotation process, the developed semi-automatic mask annotation pipeline. The pipeline consists of four steps, which are visualized in Fig. 2.
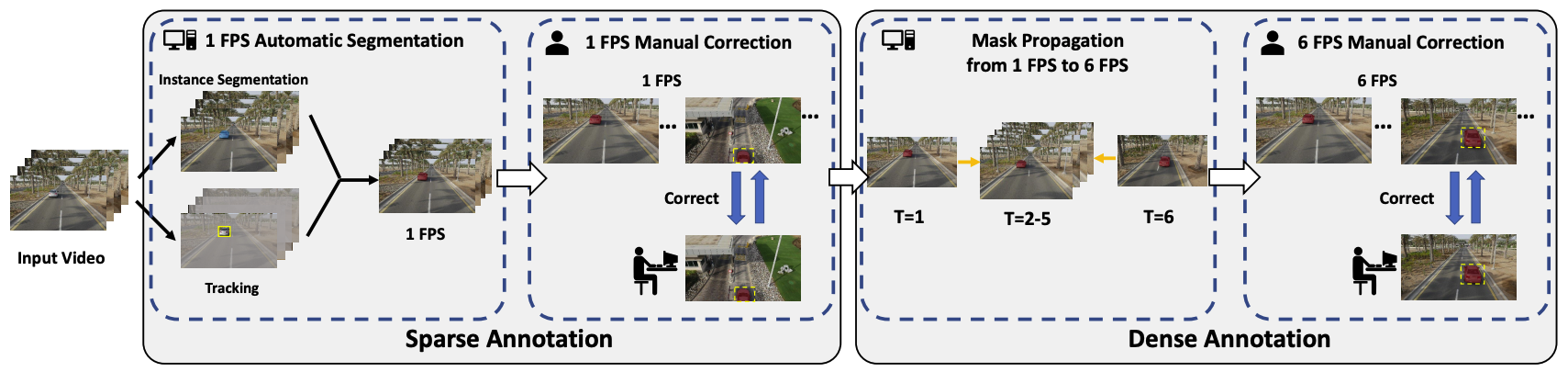
Step 1: 1 FPS Automatic Segmentation. At first, annotators manually draw the bounding box and propagate it with ARTrack. And then, they segmented the object with SAM using the bounding box annotation.
Step 2: 1 FPS Manual Correction. To fix the errors, they employ EISeg to correct to masks.
Step 3: Mask Propagation. Using VOS model, propagated the mask.
Step 4: 6 FPS Manual Correction. Manually corrected the propagated masks from VOS models.
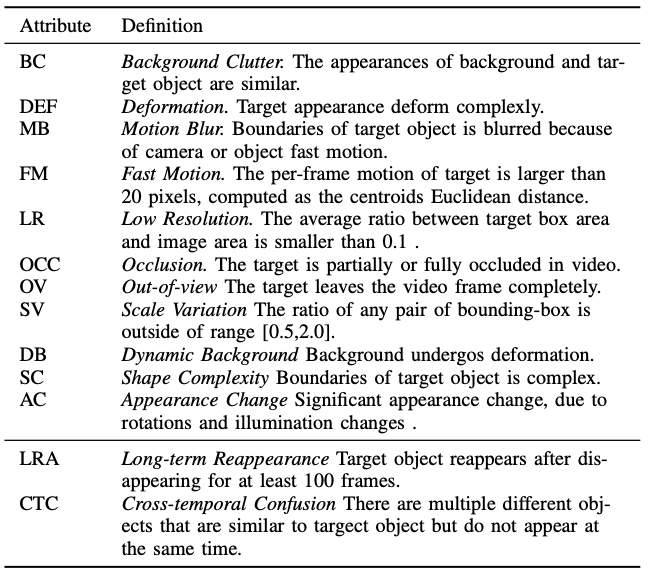 Table 2: Definitions of video attributes in LVOS.
Table 2: Definitions of video attributes in LVOS.
Attributes of the videos are shown in Fig. 2. There are 13 challenges, and each videos are labeled with the challege tags.
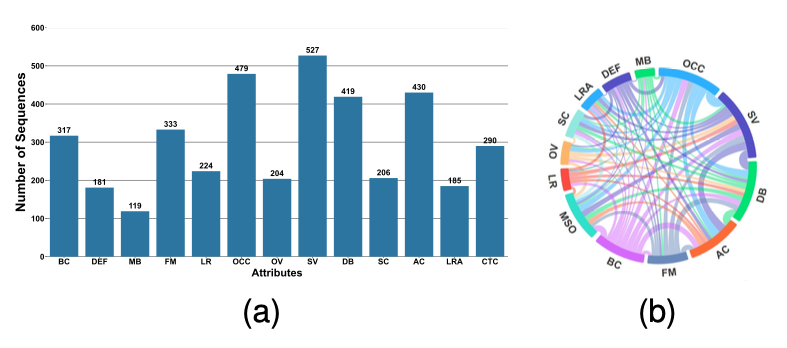 Figure 4: Attributes distribution in LVOS.
Figure 4: Attributes distribution in LVOS.
Fig. 4a and 4b illustrate the distribution of each video and the mutual dependencies.
Experiments
They made three questions to throughly assess the existing VOS methods. The questions are as follows:
- What happens when existing video object segmentations models, fitted for short-term video domains, come across long-term videos?
- Which factors are instrumental in contributing to the variance in performance?
- How to equip a video object segmentation model with the ability to handle long-term videos?
They carry out experiments in four video object segmentation tasks: semi-supervised VOS, unsupervised VOS, unsupervised multiple VOS, and interactive VOS. The 720 videos are divided into 420 for training, 140 for validation, and 160 for testing.
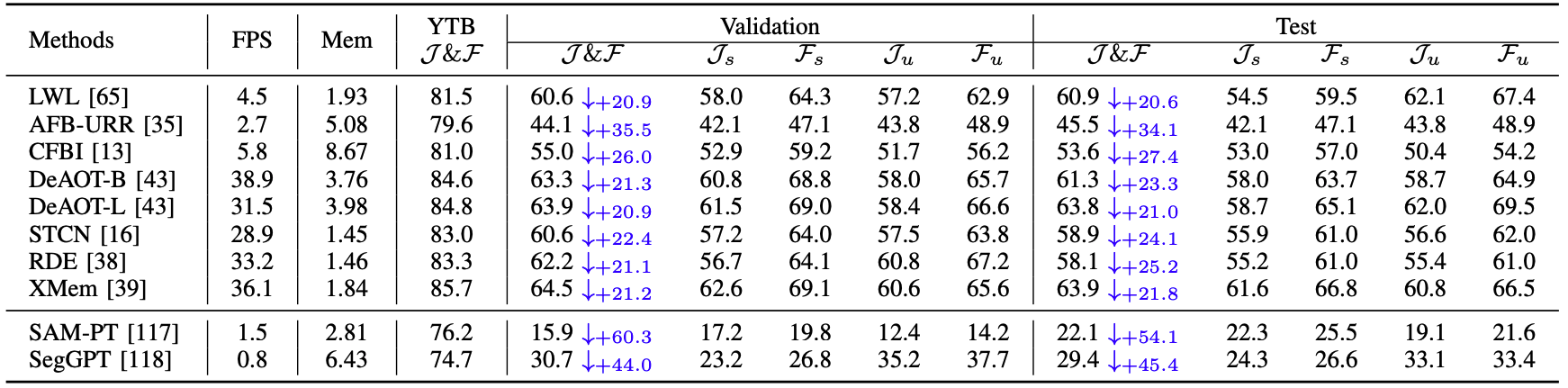 Table 3: Results of semi-supervised video object segmentation models on validation and test set.
Table 3: Results of semi-supervised video object segmentation models on validation and test set.
 Table 4: Results of unsupervised video single object segmentation models on validation and test set.
Table 4: Results of unsupervised video single object segmentation models on validation and test set.
 Table 5: Results of unsupervised video multiple object segmentation models on validation and test set.
Table 5: Results of unsupervised video multiple object segmentation models on validation and test set.
 Table 6: Results of interactive video object segmentation models on validation and test set.
Table 6: Results of interactive video object segmentation models on validation and test set.
For details, please refer the original paper.
One thing to note is, in Tab. 3, visual foundation models such as SAM-PT and SegGPT degraded much more severly than expert models.
TL;DR
LVOS is a video object segmentation dataset with long duration and severe occlusions. An exhaustive study found that existing VOS models suffer from performance degradation when tested on LVOS.
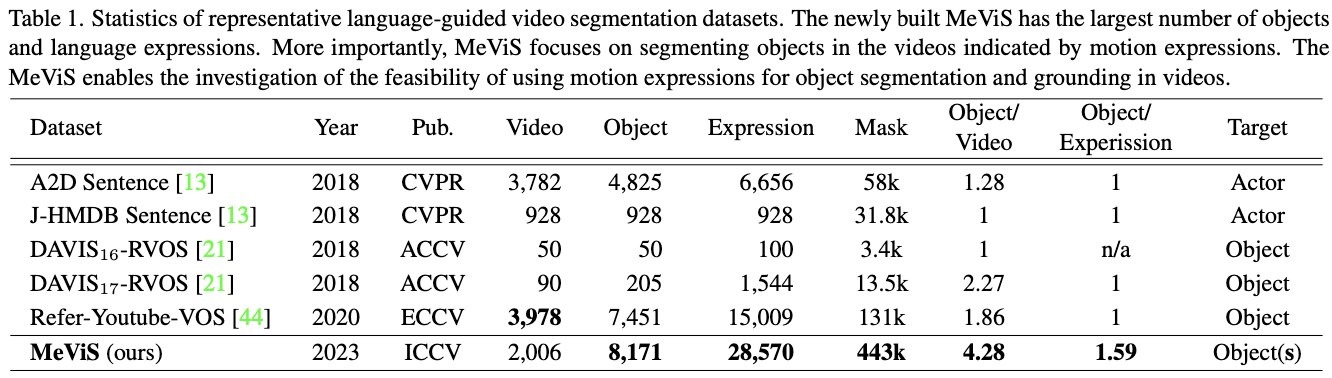
MeViS (ICCV 2023)
MeViS: A Large-scale Benchmark for Video Segmentation with Motion Expressions

Specification:
- referring VOS
- motion-guided language expression
- resolution: not specified
- # videos: 2,006
- # masks: 443k
- # objects: 8,171
- # obj. categories: N/A
- # video duration: not specified
Motivation
Existing RVOS datasets refer to salient, isolated, and visible target objects, with the corresponding expressions often containing static attributes such as object color or appearance, which can be observed in a single frame. Hence, this paper introduces a new large-scale motion-based referring video object segmentation dataset called Motion expressions Video Segmentation (MeViS). The specifications of the dataset are written above. The dataset is composed according to the principle of containing temporal clues rather than static supervision.
In addition, 5 existing RVOS methods are benchmarked. After that, a baseline approach, named Language-guided Motion Perception and Matching (LMPM), is proposed.
MeViS Dataset
Videos are collected from puiblicly available video segmentation dataset including MOSE. The objects maybe single or multi-object.
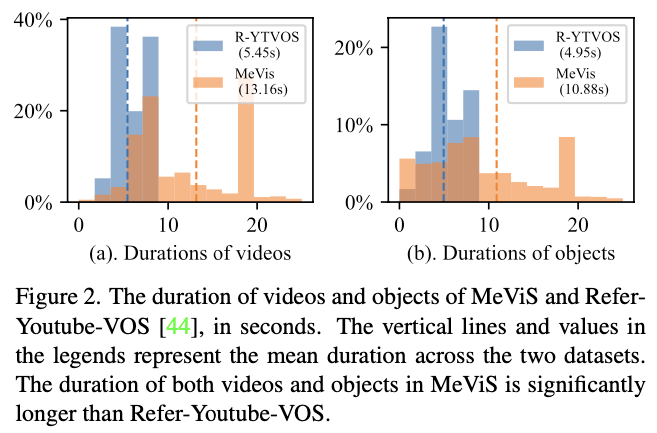


You can refer Tab. 1, Fig. 2 and Fig. 3 for dataset composition details. Also, the word cloud of the text guidance are visualized in Fig. 4.
Experiments
The videos are split into three subsets—1,712 videos for the training set, 140 videos for validation set, and 154 videos for testing set.


Tab. 2 and Tab. 3 show that temporal understanding is the key to getting good results on the MeViS dataset. TC in tab. 2 means adding an additional attention module to the model to get the temporal context. Tab. 3 shows that when the existing models are only trained on image segmentation datasets, they still perform well in RVOS datasets but stagger in the MeViS dataset, which shows that the MeViS fully exploits temporal information.
LMPM: A Simple Baseline Approach
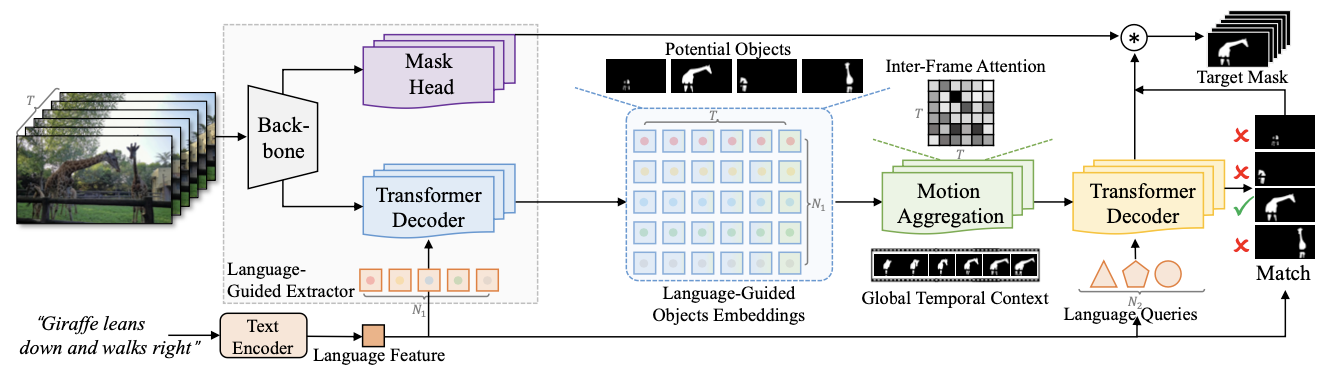
The overall architecture of LMPM is illustrated in Fig. 5. LMPM represents each object as object embeddings while generating $N_1$ language-guided queries to identify the target objects in the video across $T$ frames. Then, it performs inter-frame self-attention to add motion perception to the object embeddings. Next, by using $N_2$ language queries as the query, it gets object embeddings using the Transformer decoder. Finally, calculate the matching score with each object trajectory and filter them by matching threshold σ. Since it does not necessarily pick the best one, the target object can be more than two.

Ablation study can be found in Tab. 4.
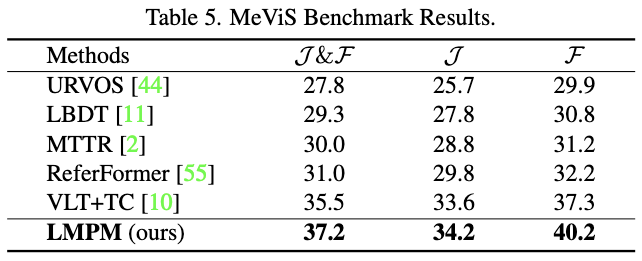

The benchmark results and qualitative results can be found in Tab. 5 and Fig. 6.
Discussions
nothing specials are written on the paper.
Further Reading
You can also refer papers below:
Discussions
- I think we need a new metric to calculate the disappearance rate of the target object in the video. (from MOSE)