ThinkVideo: High-Quality Reasoning Video Segmentation with Chain of Thoughts
- 숫자가 대단히 잘 뽑힌 논문
- 생각은 하고 있었지만 역시 paper를 쓰려면 손이 빨라야 한다
Method
- non-overlapping binary mask sequence $\hat y = \{\mathcal{M}_i \in \mathbb R ^{T\times H \times W} \}^k_{i=1}$ 를 먼저 만든다.
- 각 output mask sequence $\mathcal{M}_i = \{m_{i,t} \in \mathbb R^{H\times W}\}^T_{t=1}$는 각 object instance에 correspond하는 것이다.
- $m_{i,t} \cap m_{j,t} = \emptyset \quad \text{for } i\neq j$ 을 전제한다.1
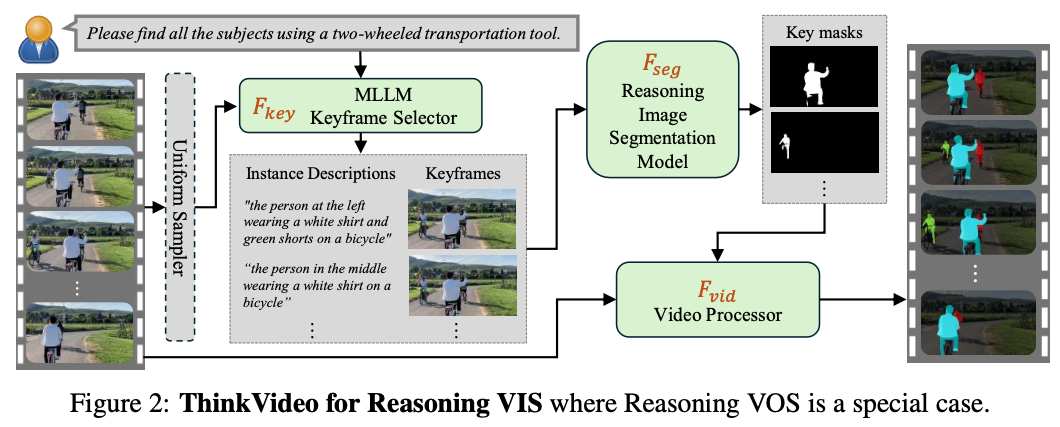
Multi-Agentic Framework
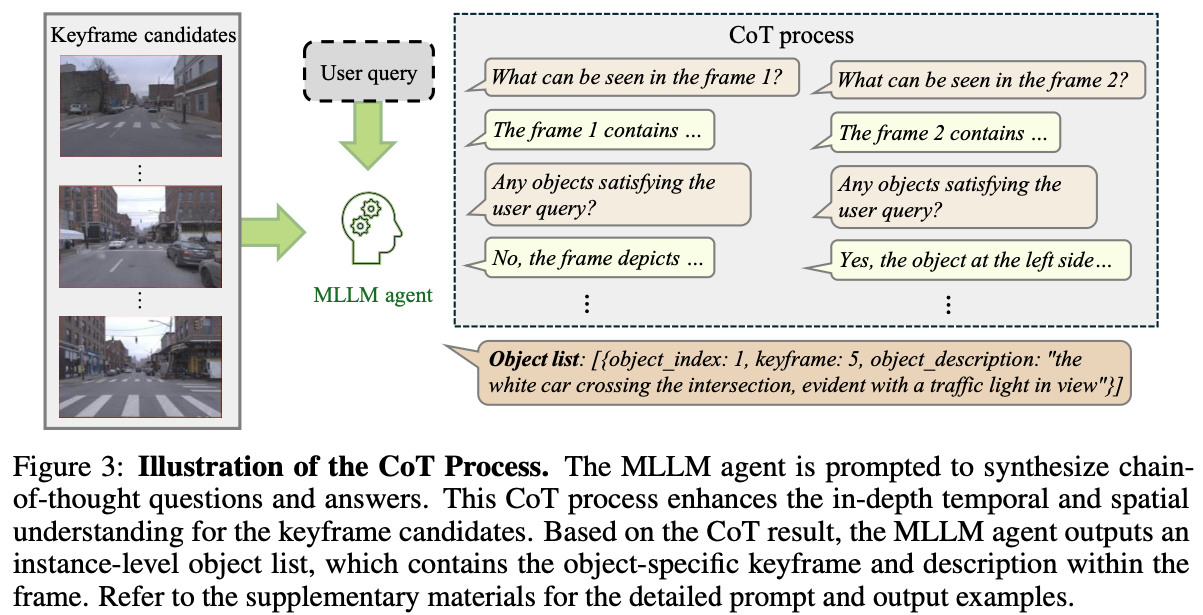
- closed source MLLM으로 keyframe을 select한다.
- GPT-4o, Gemma3를 활용한낟.
- keyframe-related object description, respective keyframe, object index를 만든다.
- CoT process를 통해서 question을 만들고, object를 찾는다.
ThinkVideo: Reasoning Video Instance Segmentation
- 주어진 video $x_v$와 user query $q$에 대해서 $T'$ keyframe candidates를 uniform sampling한다.
- keyframe candidates에서 refine된 instance-level text description $s$과 corresponding keyframe $f$을 얻는다.
- 여기서 reasoning segmentation model $\mathcal{F}_{seg}$를 사용해서 per-instance key masks $\{\tilde m _i \in \mathbb R^{H\times W}\}$를 생성한다.
- 이는 SAM2를 통해 track한다.
- overlap하지 않도록 하기 위해 optional post-processing operation을 수행하였다.
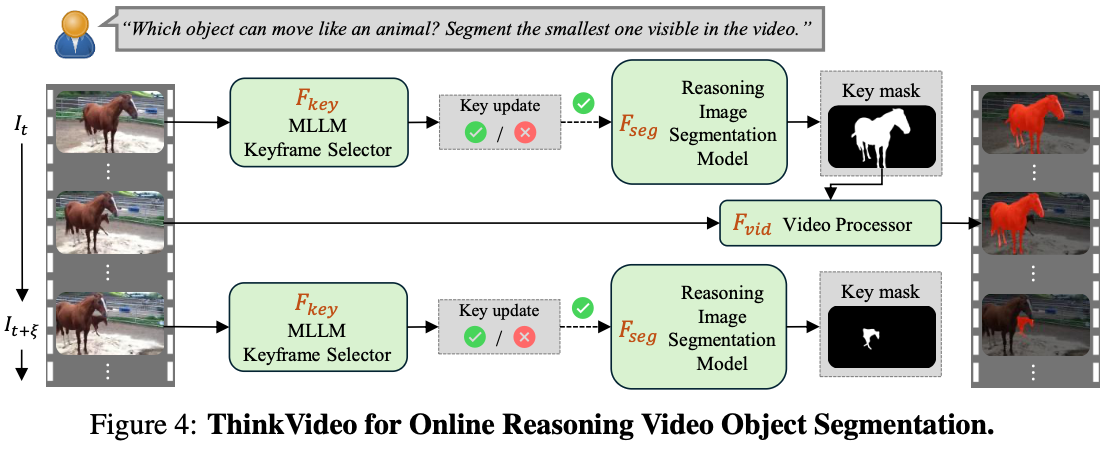
ThinkVideo: Online Reasoning Video Object Segmentation
- online video stream에 대해서다음과 같이 formulate함.
- 나머지는 동일하고, keyframe을 종종 업데이트하면서 진행하는 점만 다름.
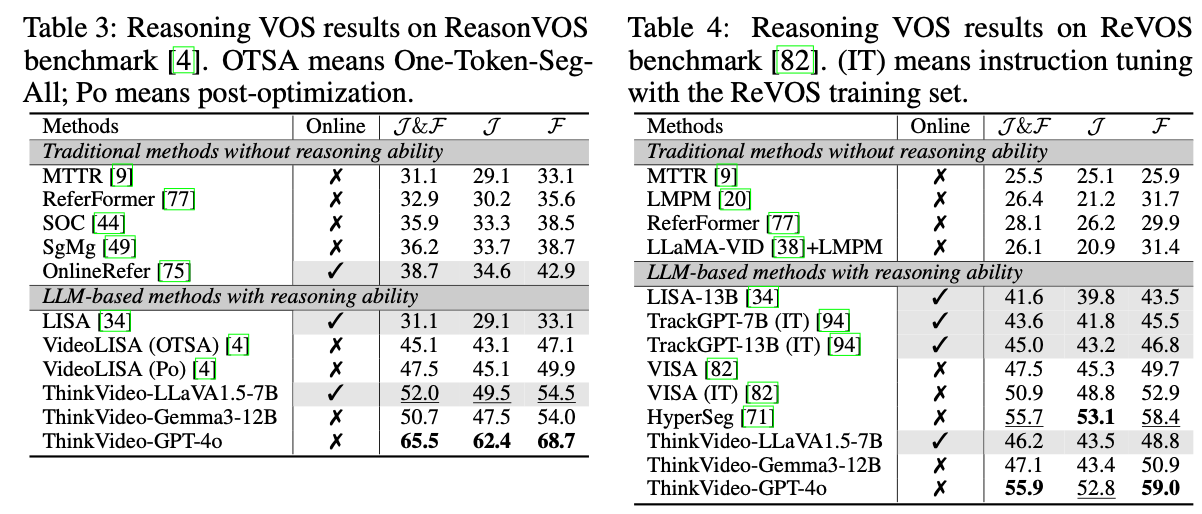
Experiments
- GPT-4o로 keyfraem select하고, LLaVA1.5-7B, Gemma3-12B로 online ThinkVideo에 활용
- image reasoning segmentation model에 대해서는 Seg-Zero 사용
- tracker로는 SAM2 사용

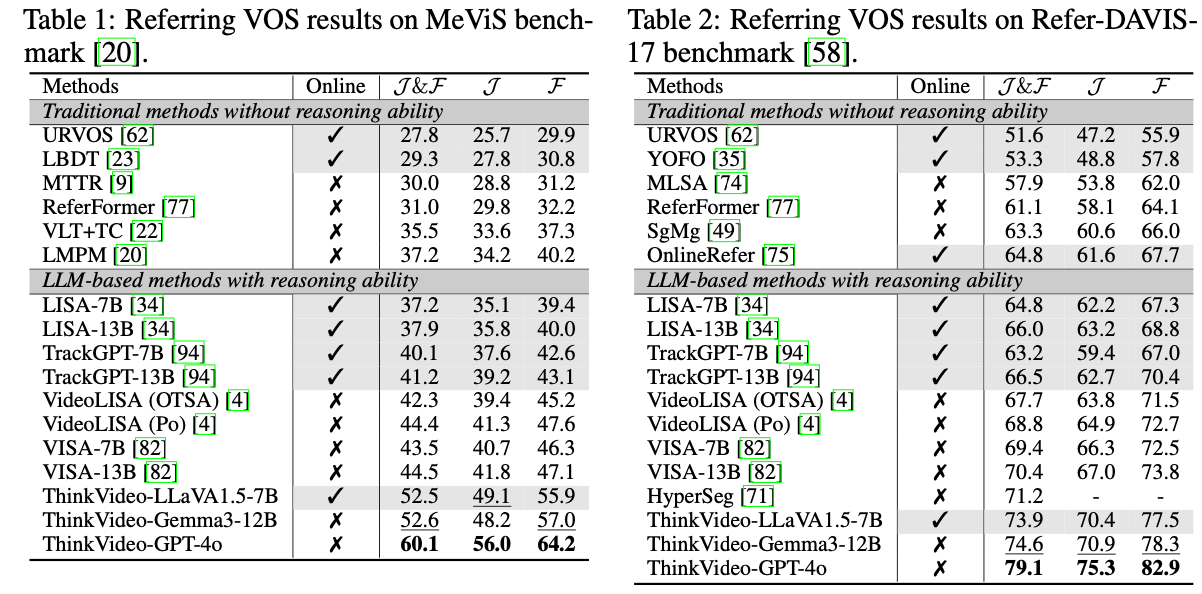
- 대단히 높은 숫자를 확인할 수 있음.


Discussion
- 요즘 Reasoning VOS의 질문들은 특히나 너무 어려워서 text 대답을 먼저 내놓고 푸는 건 효과가 있을 수 있다.
- 이걸 GPT한테 시키는 건 좋은 발상
- but end-to-end 단에서의 고민도 필요하긴 할듯
- 그에 대한 reasoning step guidance가 포함된 dataset이 없는 부분은 한계이다.
Footnotes
학습 시에는 특정 guidance 없이 달성하기는 꽤 어렵다. ↩︎