Referring Video Object Segmentation via Language-aligned Track Selection
Motivation
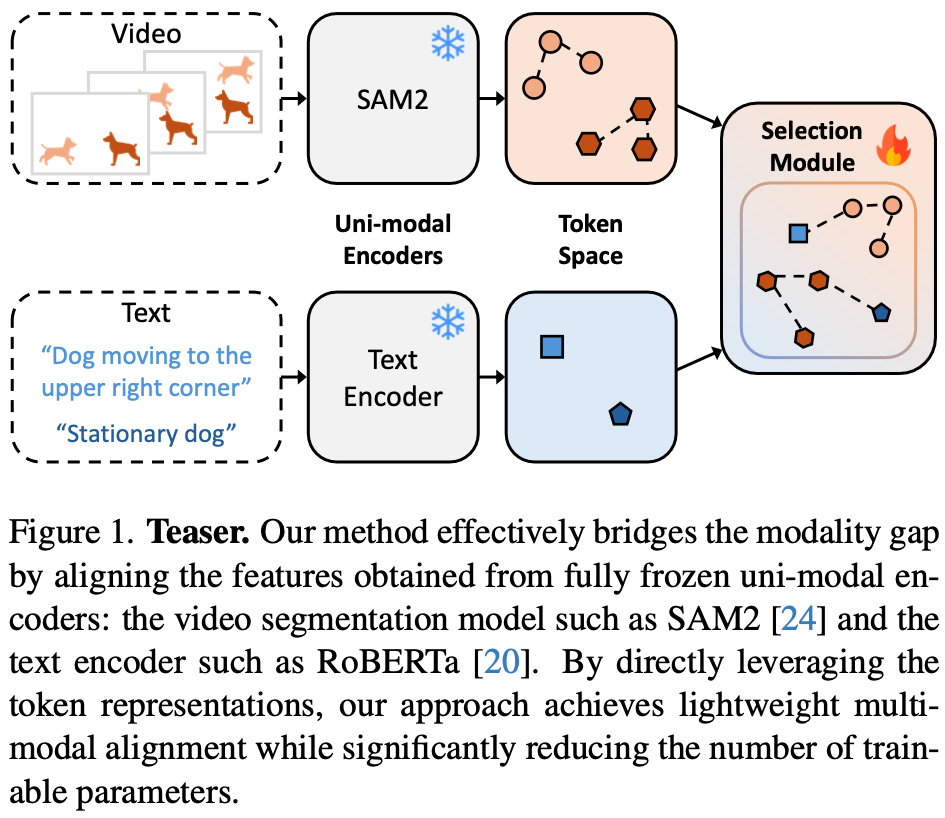
- SAM2의 object token은 temporal-aware object information를 encode하고 있음.
- 이를 이용한 RVOS model을 만듦.
Method
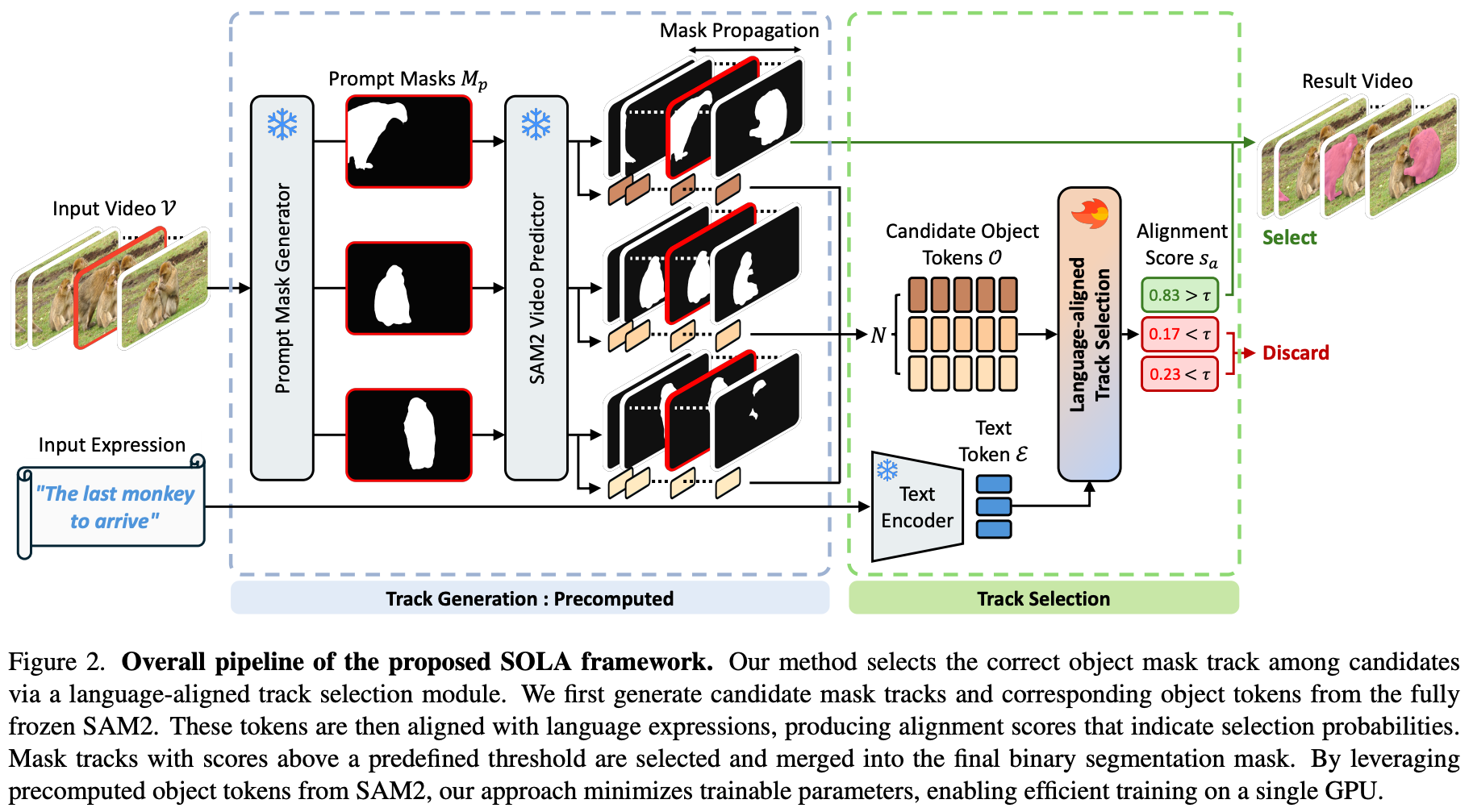
Track Generation
- SAM2가 모든 mask track을 만들도록 함.
- 중간에 등장하는 object의 가능성을 위해, predefined frame interval로 frame selection해서 mask generation함.
- Image predictor로 뽑은 다음에 Video predictor로 propagate함.
Object Representation
- mask마다 object pointer $O^{i,t}$가 나옴.
- 이를 모아서 concatenate하여 temporal dim도 추가한 object token $O^i$를 만듦.
- object의 motion에 대한 정보를 포함할 것이라고 assume함.
Track Selection
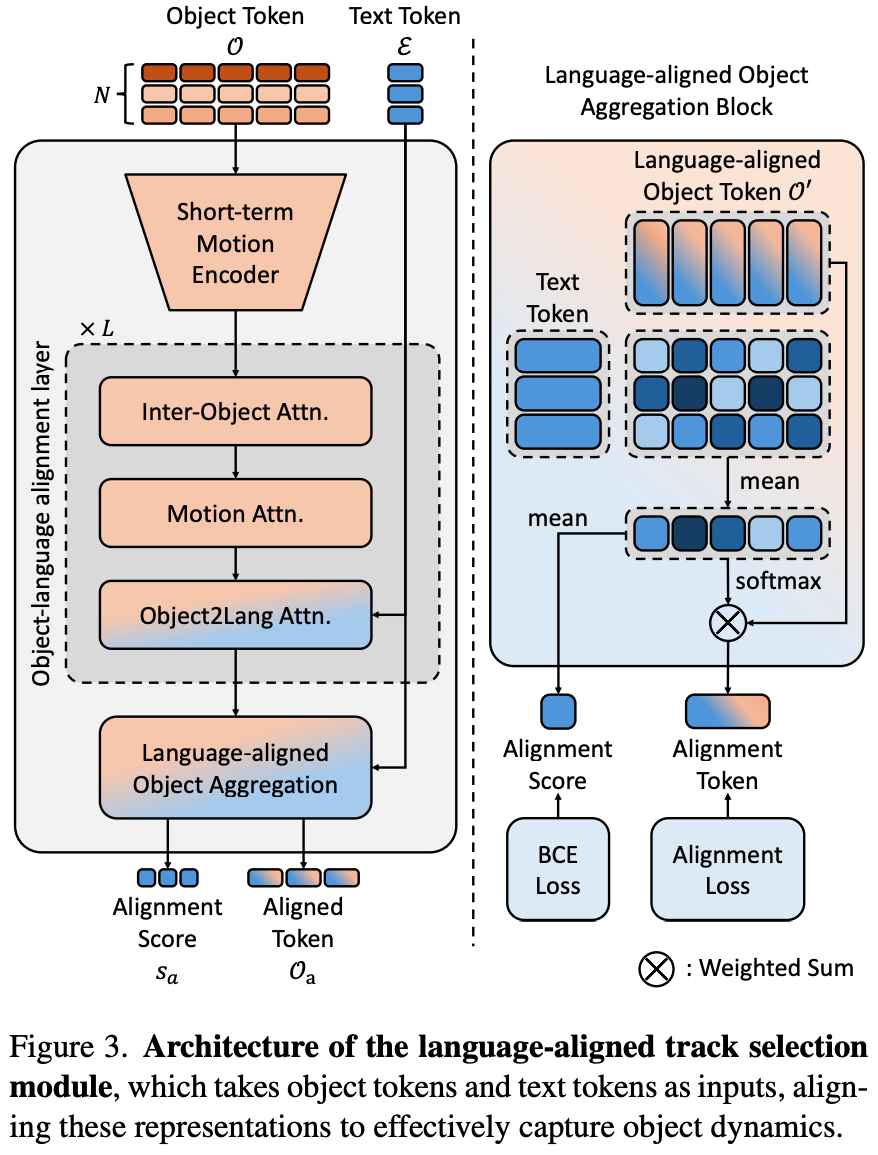
- a lightweight language-aligned track selection module을 정의함.
- text token과 align되는 몇 개의 token만 select함.
- Motion encoder
- $O^i$를 1D convolution으로 temporal dim을 줄여 $ℝ^{T^'×D}$로 줄임.
- Object-language alignment layer
- language와 object를 포함하는 CA와 SA layer
- alignment token $O'\in ℝ^{N×T^'×D}$를 생성.
- Language-aligned object aggregation
- weighted sum of object token $O_a \in ℝ^{N×D}$를 생성.
- $$w_a = \text{softmax}(Avg_{N_w}(O' E^T))$$
- 얻은 각 object score는 $[0,1]$로 mapping
- threshold $τ$를 넘으면 select, 아니면 discard
- weighted sum of object token $O_a \in ℝ^{N×D}$를 생성.
Experiment
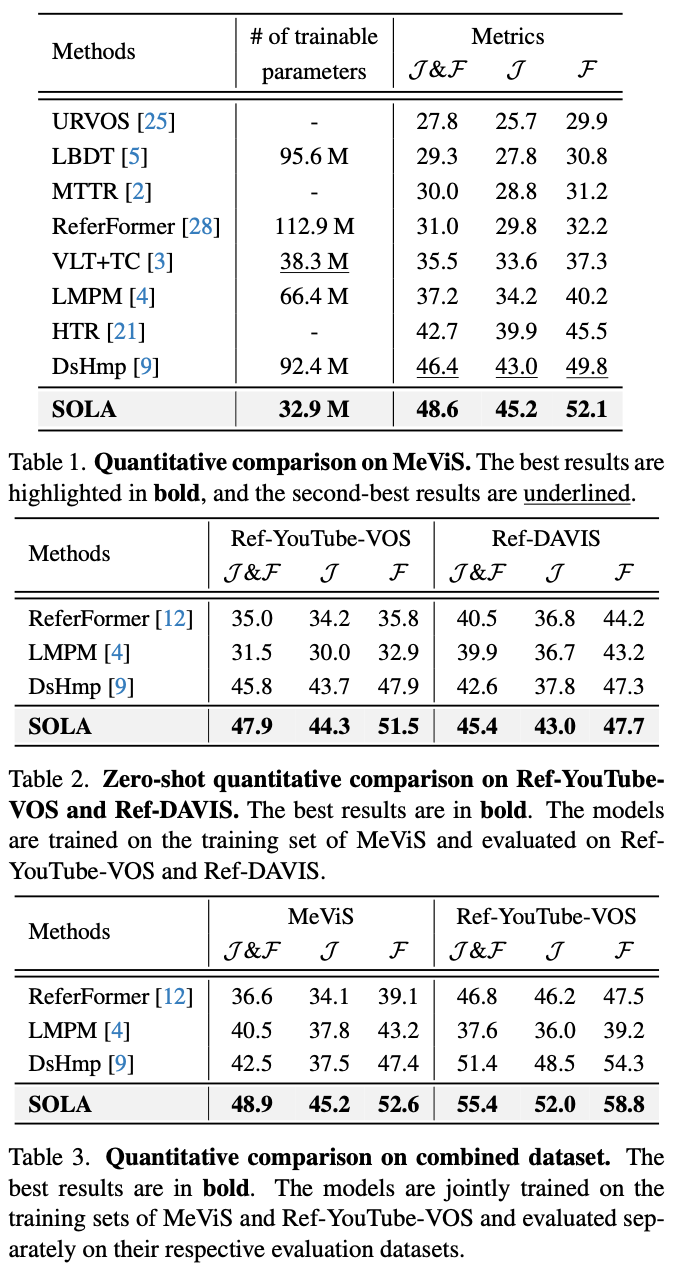
Discussion
- 가벼운 모델과 인상적인 숫자 – 상당히 좋은 방법
- straightforward한 접근방법
- VLM을 썼으면 어땠을지?