Introduction
Referring Video Object Segmentation (RVOS) is the process of segmenting and tracking objects in a video based on provided textual descriptions. As discussed in this page, segmentation is a fundamental process for understanding and memorizing objects and events for human beings. Therefore, to enable machines to comprehensively understand videos, it is essential to perform VOS and connect the segmentation masks with language space via RVOS. This post will provide an overview of existing datasets in RVOS datasets and recent advances in the field.
A2D Sentence (CVPR 2018 Oral)
Actor and Action Video Segmentation from a Sentence

Motivation
A2D Sentences is the first VOS dataset that uses natural language input sentences to guide the target object. In this paper, the A2D Sentences dataset, which aims to the pixel-level segmentation of an actor and its action in video. Previous A2D dataset created an actor-action segmentation dataset, but it remains at the word level. This paper proposes a new dataset to segment actors and their actions by the sentence form textual guidance, as illustrated in Fig. 1.
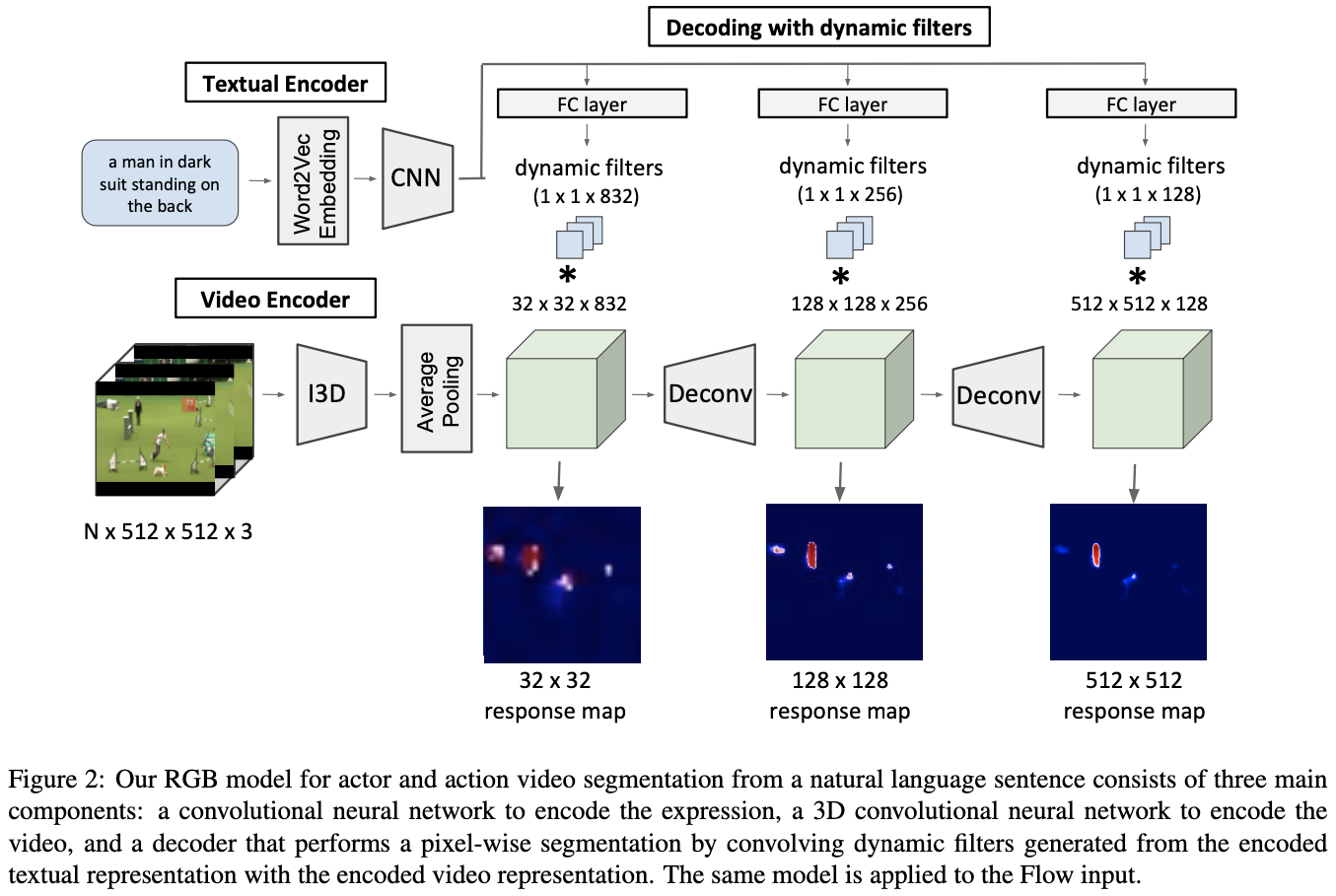
This paper also introduces a CNN-based baseline method, as shown in Fig. 2. However, I think it is slightly outdated, and the methodologies are beyond the scope of this post. So I will not go into details, but if you are interested in the method, please refer to the original paper.
A2D Sentences Dataset
Actually, the A2D Sentences dataset is composed of two parts: A2D Sentences and J-HMDB Sentences. For the sake of brevity, I will use A2D Sentences for the combine of two dataset afterward. In this section, this post will reviews the each part.
A2D Sentences
For 3,782 videos in the A2D dataset, They re-annotated the videos in a total of 6,656 sentences, including 811 different nouns, 225 verbs and 189 adjectives. It is worth to note that some nouns like adult in A2D is annotated with man, woman, person and player, while action rolling may also refer to flipping, sliding, moving, and running for finer graunularity.
J-HMDB Sentences
J-HMDB dataset contains 928 video clips of 21 different actions. This videos are reannotated too, resulting 928 sentences, including 158 different nouns, 53 verbs and 23 adjectives.

The examples of annotated videos can be seen in Fig. 3.
Experiments
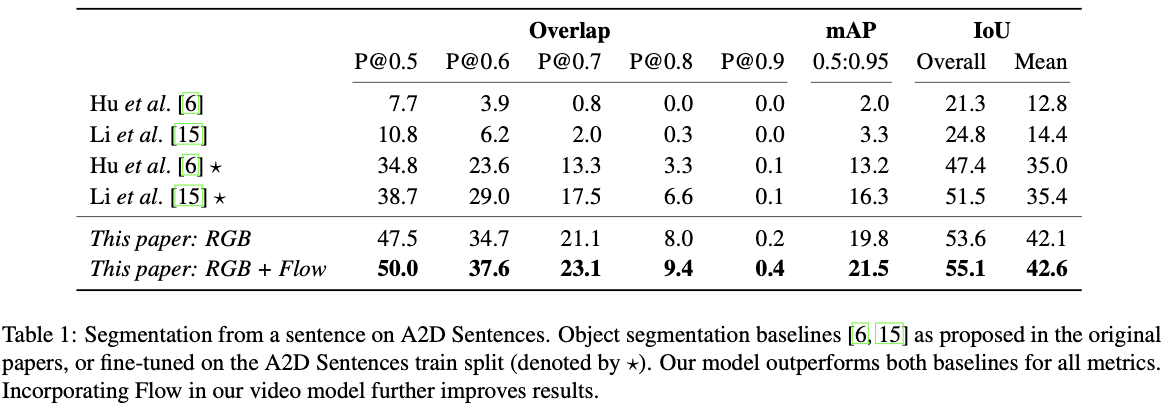

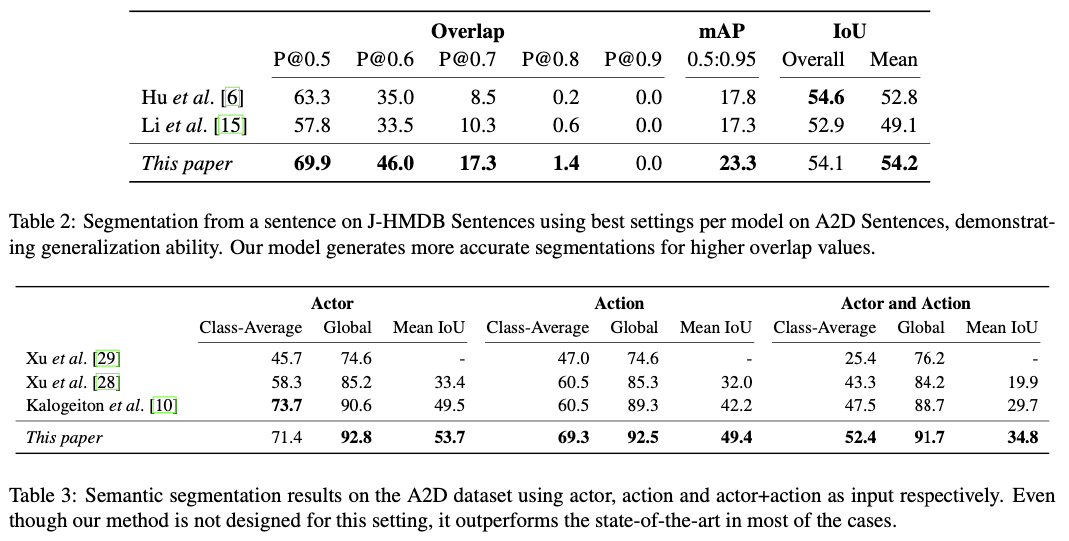
I will omit the details. Please refer to the original paper for details.
Ref-DAVIS (ACCV 2018)
Video Object Segmentation with Language Referring Expressions

Motivation
This paper also propose RVOS task—segmenting objects in video using language referring expressions.
This paper and the A2D Sentences paper are published almost at the same time, say March 2018. The difference between the two dataset is that Ref-DAVIS is more focused on the statis features, which can be spotted only using the image-level feature extraction.
Ref-DAVIS Dataset
The videos from DAVIS_16 and DAVIS_17. DAVIS_16 consists of 30 training and 20 test videos with single objects, while DAVIS_17 have 60 training and 30 val/test videos with multiple objects in more complex scenes.

First frame annotation. To generate the annoatations, they followed this way and asked the annotator to provide langauge description of the mask of an object by looking only at the first frame of the video. Then the language description and the first frame is provided to the second annotator. If the second annotator get fail to pinpoint the referred object correctly, then the language expression is regarded as ambiguous and corrected.
Full video annotation. On DAVIS_17, the annotators are also asked to generate a referring expression after watching the full video.
Overall augmented DAVIS_16/17 contains about 1.2k referring expressions for more than 400 objects on 150 videos with ~10k frames.
Method and Experiments

The method and experiemental results are beyond the scope of this post. So I left this section blank.
Refer-YouTube-VOS (ECCV 2020)
URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
Specification(Full-video expression):
- resolution: same to YouTube-VOS
- # videos: 3,975
- # ref. expr.: 27,000+
- # FPS: 30 (video) → annotations every 5 frames
- # objects: 6,388(train), 1,063(validation)1
- # expressions: 27,899
- # video duration:

Motivation

This paper introduces Refer-YouTube-VOS dataset, in the task of referring video object segmentation (RVOS).
iDeA: It is quite obvious that this paper is not the first paper canonically defining the video object segmentation with language guidance task. But the exact term “RVOS” first appeared in this paper, and the size of the dataset has greatly increased.
Plus, this paper points out that the naïve method to accomplish this task is using image segmentation models, either using them all frames independently or choosing some anchor frame and propagate it. However, the limitations of such methods are apparent because of temporal coherency and the chance of picking the wrong anchor frame, respectively.
Refer-YouTube-VOS Dataset
The Refer-YouTube-VOS dataset is constructed based on the YouTube-VOS (ECCV 2018) dataset. They employed Amazon Mechnical Turk to annotate expressions. Each annotator is given the original video and the mask-overlaid video, and then asked to provide a description of the target object within 20 words. There are two kinds of annotations—Full-video expression and First-frame expression. After that, objects were dropped if it cannot be localized solely using the referring expression.
The quantitative comparison against the existing datasets and the qualitative visualization are provided in Tab. 1 and Fig. 1, respectively.
Methods
Please refer to the original paper for details.
Discussion

Limitation. In Fig. 5, only static features of the target objects are provided. Therefore, understanding video comprehensively is not important in this task.
MeViS (ICCV 2023)
Please check this post.
ReVOS (ECCV 2024)
Please check this post.
the original YouTube-VOS has 6,459 unique objects in train set and 1,063 unique objects in validation set. (util rate: 5,388/6,459 = 98.9%(train set), 1,063/1,063 = 100%(val. set)) ↩︎