Motivation
- GroundingDINO에서 영감을 받은 vision-language model
- 세 가지 구조를 제시함
- object-consistent temporal enhancer
- grounding-guided deformable mask decoder
- condifence aware query pruning strategy
Method
- GroudingDINO 1 2
- text-guided object detection model
- language-align되지 않은 vision 모델 사용
- text encoder와 image feature를 cross-attention해서 얻은 값을 query로 사용
- DETR-based detection 3
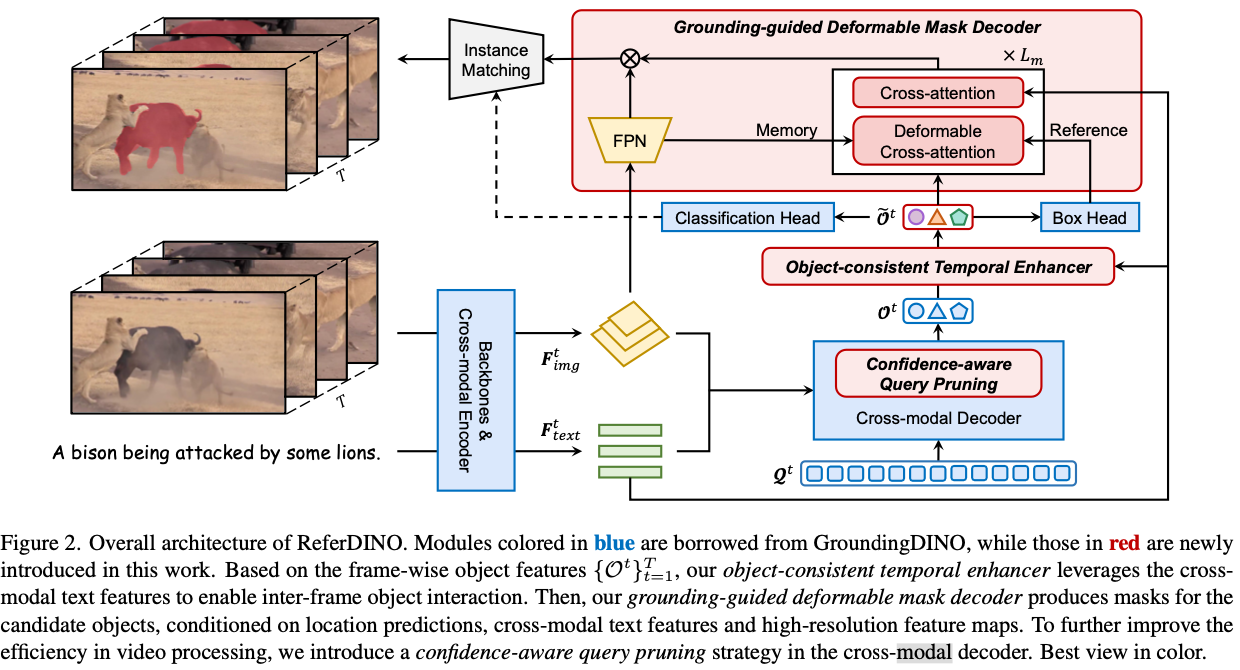
- 기본적으로는 GroundingDINO의 구조를 따름
- video domain에 적용하기 위한 모듈이 추가된 것
- 먼저 swin하고 text encoder로 feature 추출
- 매 frame을 tracking하는 방식으로 mask 생성
- Swin 계열 image encoder를 쓰고 memory를 추가한 방식
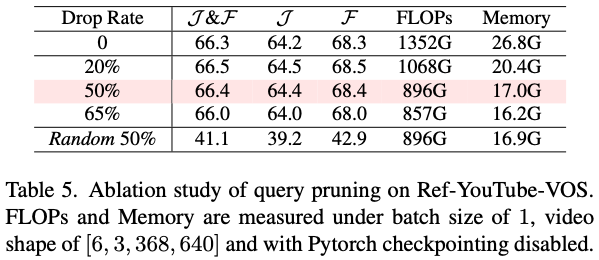
Confidence Aware Query Pruning
- object query $O$ 만들때 들어가는 learnable query $Q$의 pruning
- $GroundingDINO$에서는 900개 사용
- confidence score ㅁ나들어서 prune함.
Object Consistent Temporal Enhancer
- 간단히 말해 memory임
- 매 frame $t$에 object query $O^t$가 존재함
- memory $M^t$는 $t$ frame의 정보 저장
- init $M^1 = O^1$
- aligned object embedding
- memory 반영하여 object query 생성
- $\hat O^t = \text{Hungarian}(M^{t-1}, O^t)$
- memory update
- $M^t = (1-α\cdot \mathbb {c}^t )\cdot M^{t-1} + \alpha \cdot \mathbb {c} ^t \cdot \hat O ^t$
- $\mathbb c^t$는 sentence embedding과 object embedding의 cosine similarity
Grounding-guided Deformable Mask Decoder
Experiments
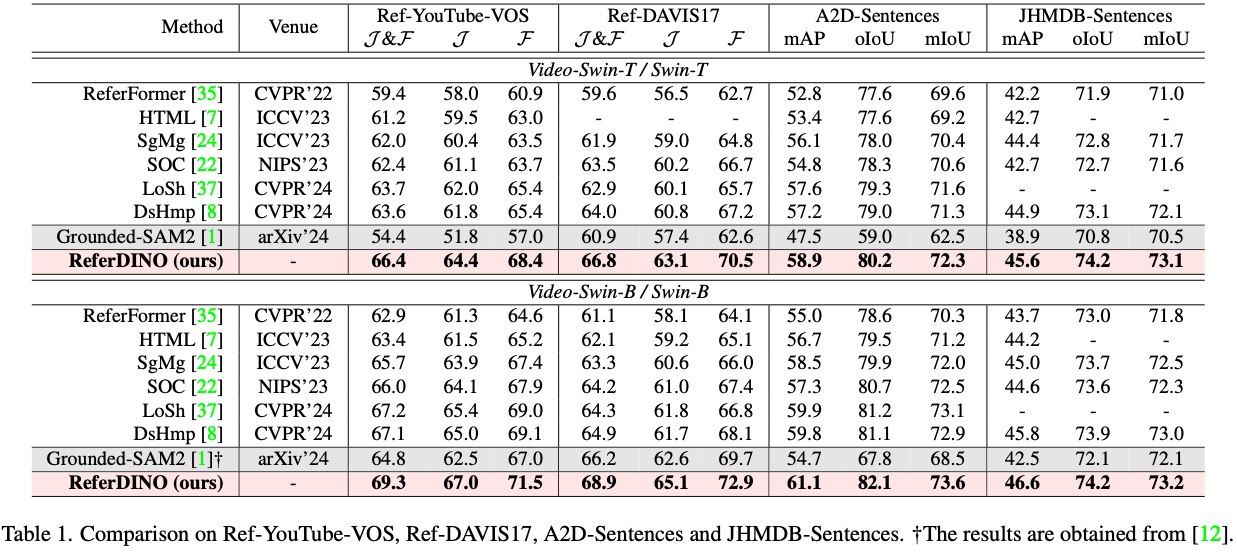
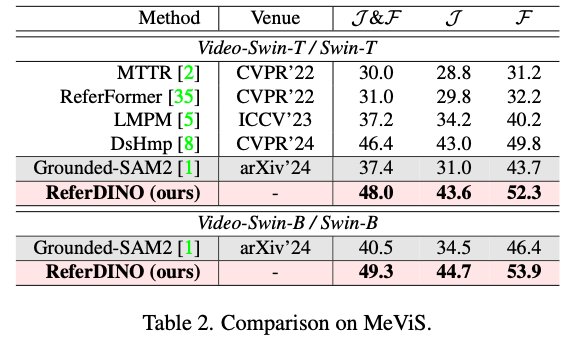
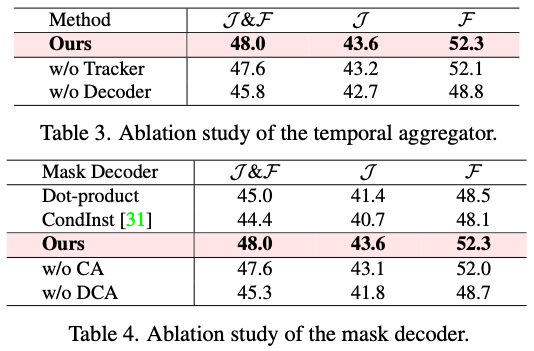
Discussion
- #1 왜 VLM-based model들은 언급하지 않는지?
- 차라리 언급하고 VLM 사용의 단점에 대해 이야기하고 넘어가는 것이 나았을 듯
- #2 특별한 것 없이 GroundingDINO를 extend한 것