MOVE: Motion-Guided Few-Shot Video Object Segmentation
Abstract

- FSVOS (Few-Shot Video Object Segmentation)
- 이미지를 보고 정의된 object를 video에서 찾는 문제
- 기존 FSVOS의 문제로 class 등의 static attribute가 지정됨을 지적함.
- MOVE (MOtion-guided Few-shot Video object sEgmentation) 제안
- DMA (Decoupled Motion-Appearance Network) 제안
Introduction
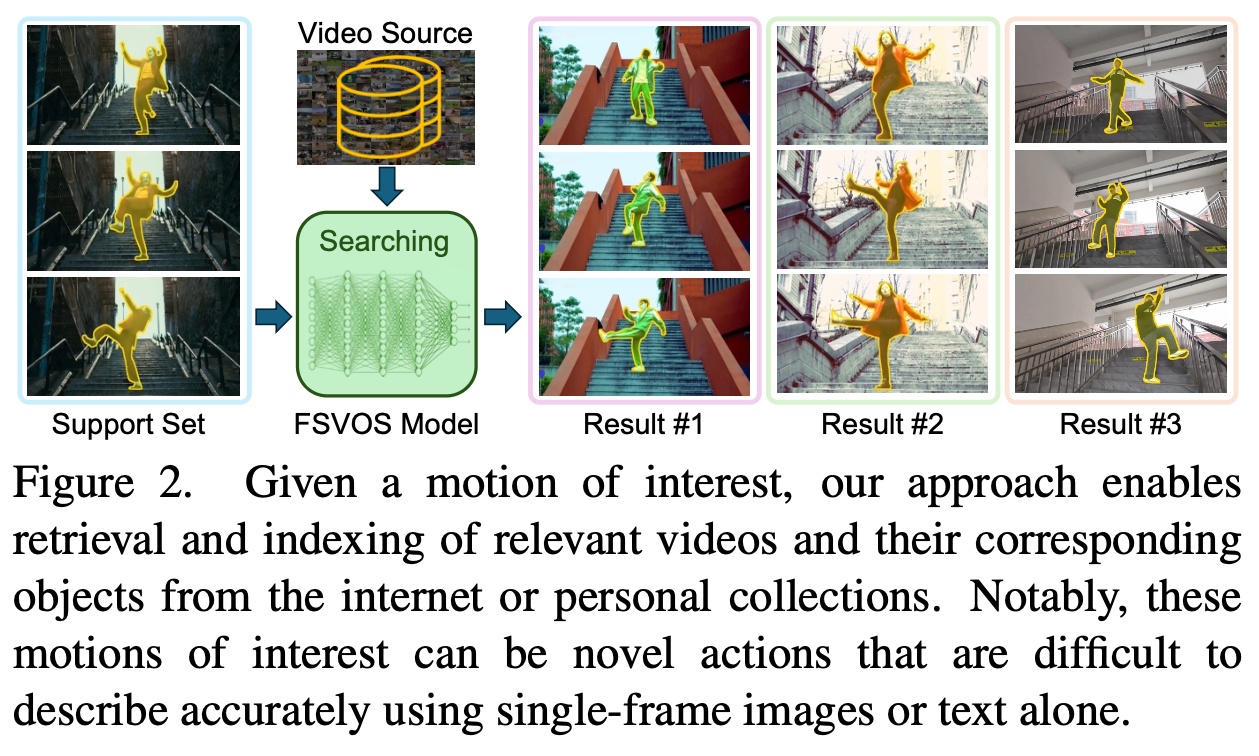
- RVOS는 text로 표현이 어려운 complex motion에 대한 referring이 불가능함.
- MOVE 제안
- 224 motion category
- 4,300 videos, 261,920 frames
- 314,619 segmentation masks
- 5,135 objects across 88 categories
- 기존 FSVOS와 달리 video를 통해 motion을 정의하고, 이를 guidance로 제공
Method
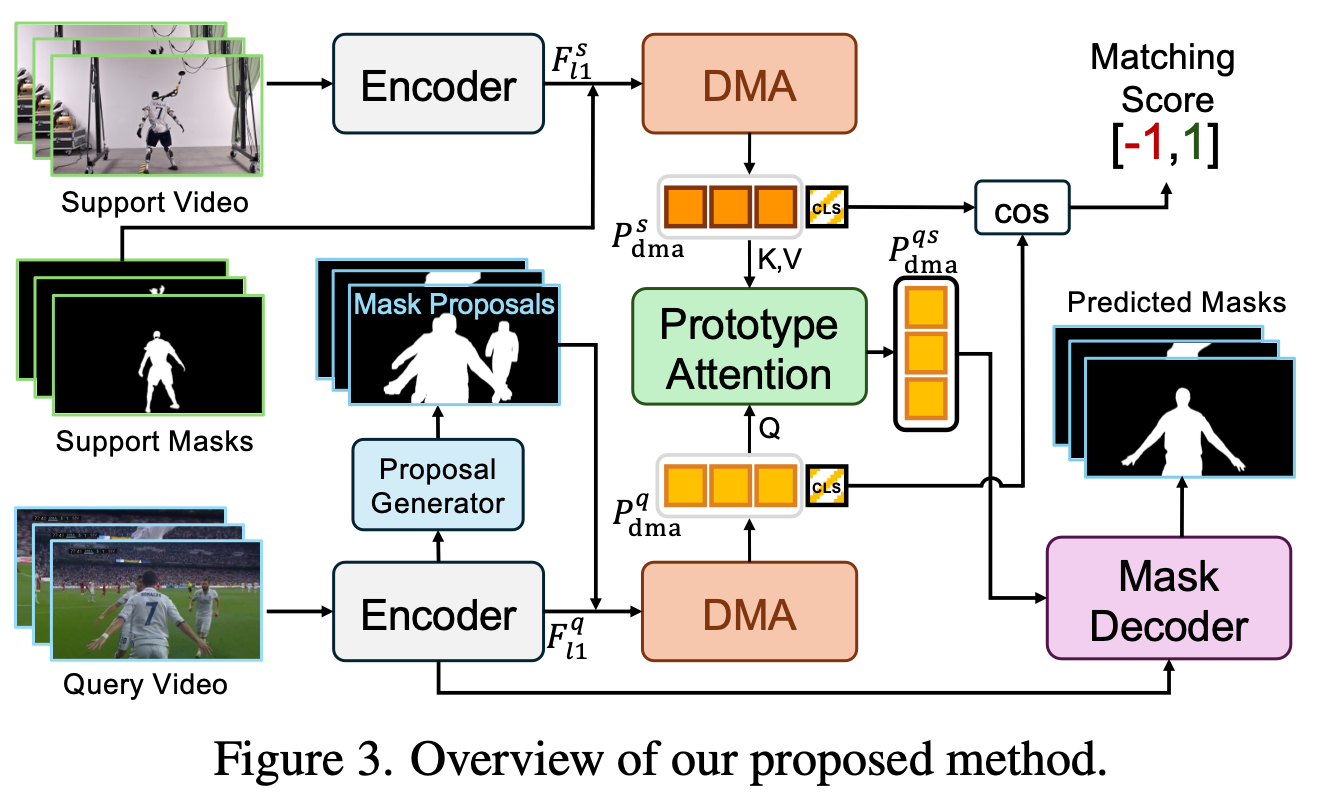
Prototype Generation
proposal generator가 proposal mask를 만든다.
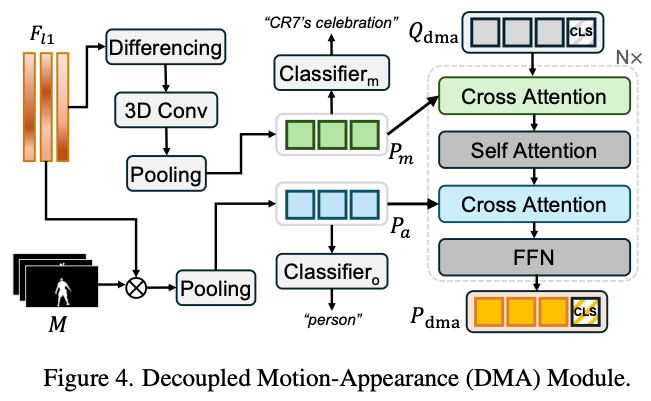
DMA는 coarse feature와 element-wise multiplication으로 prototype $P_a$를 만든다.
- 이를 appearance prototype이라고 한다. $$ P_a = \frac{\sum_{h,w}F_{l1}\odot M}{\sum_{h,w} M} \in \mathbb{R}^{T\times d} $$
- $$ D_{l1,t} = F_{l1,t+1} - F_{l1,t}, t=1,\dots, T-1, \\ P_m = \text{Pooling}(\text{Conv3D}(D_{l1}))\in \mathbb{R}^{T\times d} $$
- $$ p_o = \text{Classifier}_o (\text{AvgPool} (P_a)) \in \mathbb{R}^{C_o}\\ p_m = \text{Classifier}_m (\text{AvgPool} (P_m)) \in \mathbb{R}^{C_m}\\ $$
$C_o$는 predefined object categories, $C_m$은 number of motion categories이다.
- 각각 head는 object와 motion 정보에 집중하는 head라고 볼 수 있다.
Prototype Attention and Mask Prediction
- 여기에 Support video prototype과 query video prototype을 cross-attention해서 $P^{qs}_{dma}$를 얻는다.
- 이때
[CLS]token을 추가하여 matching score 계산에 사용한다.- $\cos$는 cosine similarity이다. $$ S_\text{match} = \cos(\texttt{[CLS]}_s ,\texttt{[CLS]}_q) $$
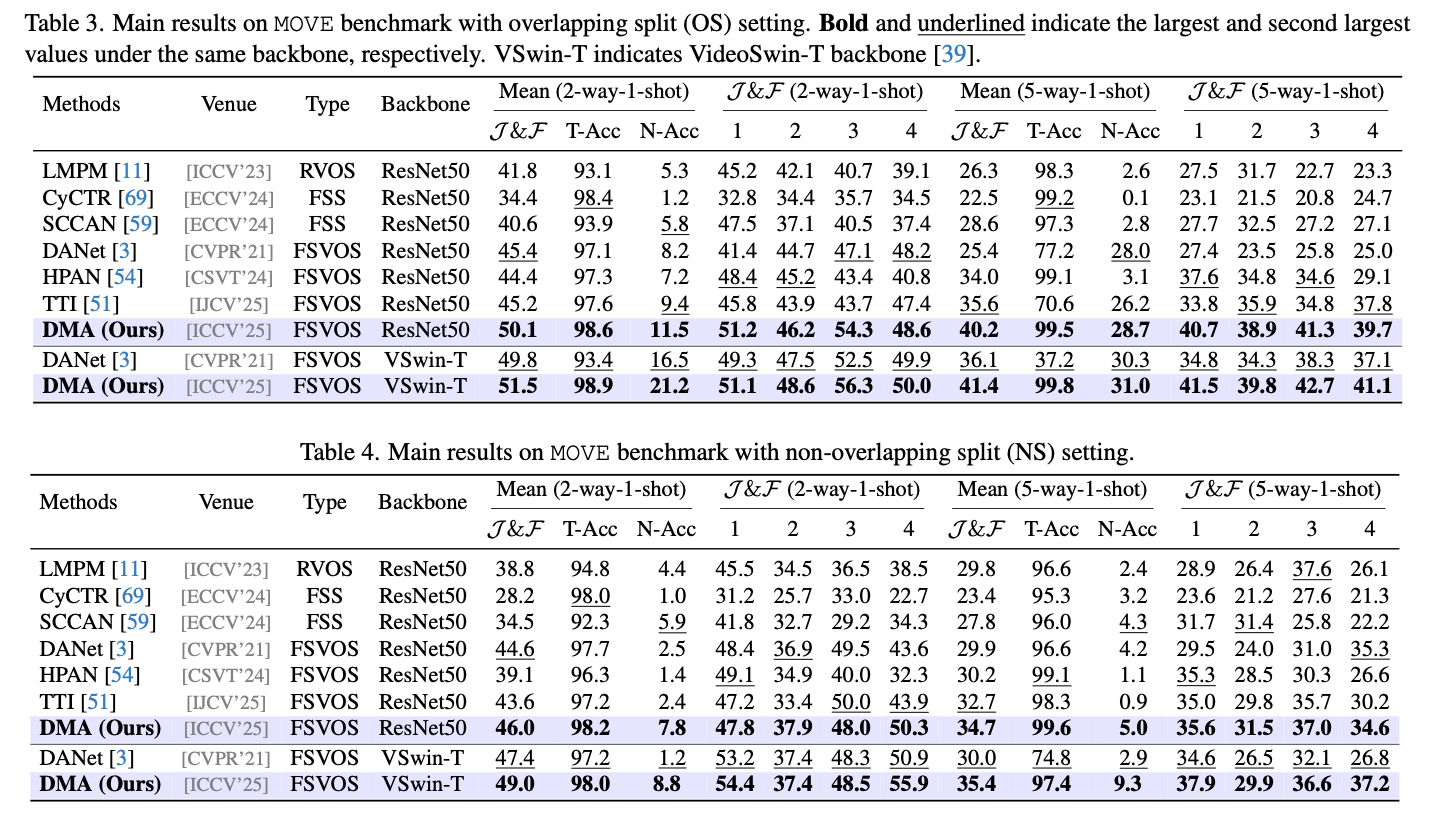
Results

Discussion
- task 자체는 신선함.