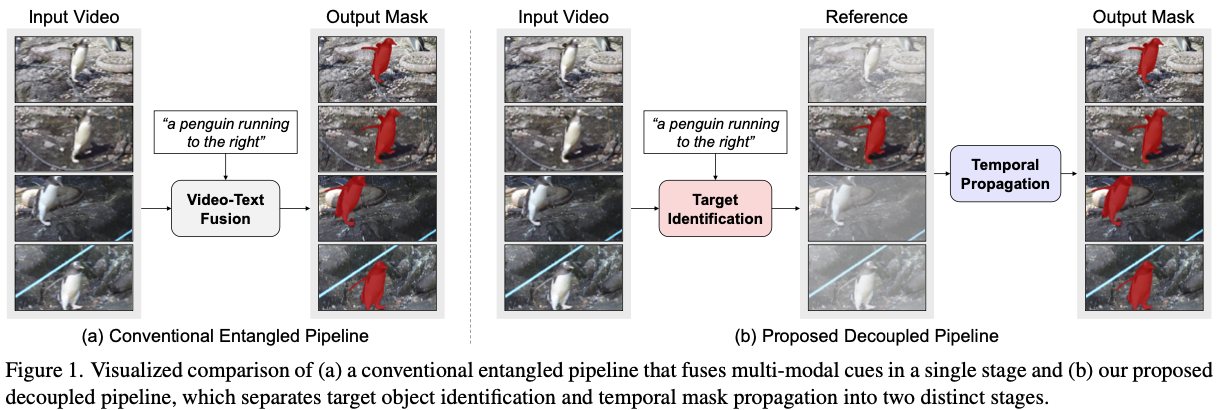
Motivation
- 기존 approach의 RVOS target 설정은 ambiguous함.
- visual feature와 textual feature가 highly entangle되어 있음.
- 비슷한 object가 많을 때 fail함.
- keyframe에서 target identification하는 과정과 mask propagation을 분리함.
→매우 동의하기 어렵다. 기존의 VISA에서도 target identification 먼저 하고 propagation한다.
Method
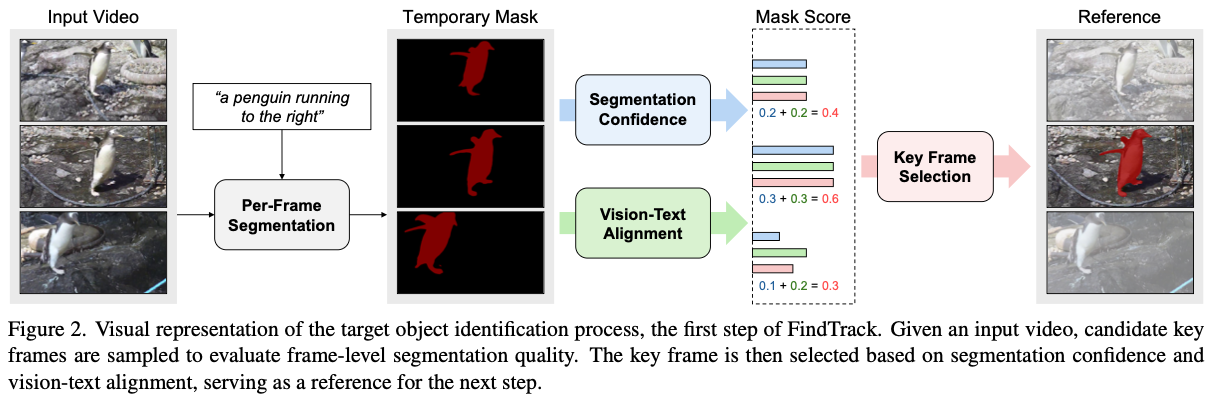
- target identification과 mask propagation을 분리한다.
Target Identification
- 먼저 모든 frame을 uniform하게 추출하여 candidate keyframes $C$를 얻는다.
- EVF-SAM 1 으로 가능한 temporal mask와 segmentation confidence $π$를 계산한다.
- mask의 confidence score가 가장 높은 것은 keyframe으로 선택한다.
- Alpha-CLIP으로 vision-text alignment score를 측정해서, keyframe이 text prompt와 align됨을 ensure한다.
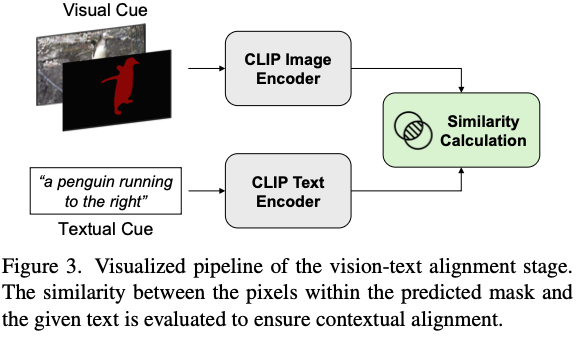
- mask score $σ=w_1π+w_2ρ$로 계산된다.
- $π$는 mask confidence score
- $ρ$는 vision-text alignment score
- $w_i$는 weight paraemters
Temporal Propagation
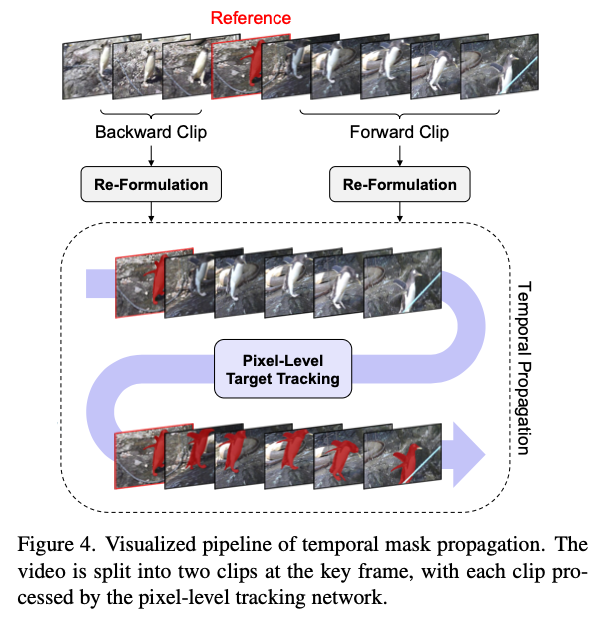
- Cutie 2로 temporal propagation함.
→왜 SAM2 안썼는지?
Experiment
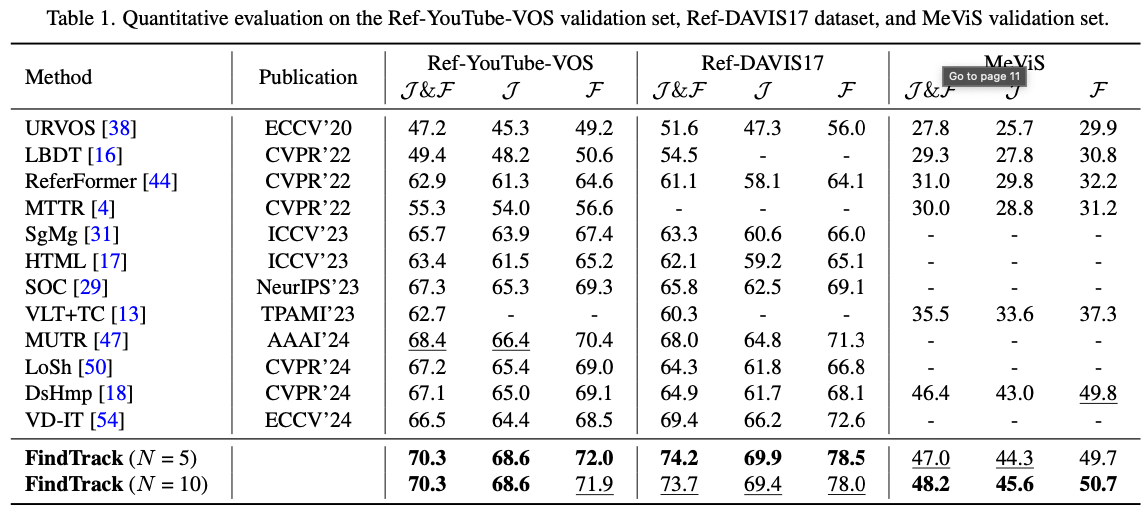 → 숫자는 좋은 편이다.
→ 숫자는 좋은 편이다.
Dicussion
- SAM 2를 안 쓰는 이유가 명확하지 않음. keyframe 추출과 initial mask generation을 제외한 모든 process는 SAM 2로 대체될 수 있음.
- 그렇게 되면 이 paper의 contribution은 segmentation confidence를 추가적으로 활용했다는 점이 유일함.
- 이 점에는 동의함. semantic keyframe이 언제나 좋은 anchor frame을 제공하는 것은 아님.
- 그러나 semantic keyframe을 uniform하게 sampling한 뒤 쓰는 것은 동의하기 어려움.
- 차라리 SAM 2를 쓰고 keyframe을 SAM 2의 memory에 넣는 방식(SAM2Long, SAMURAI, DAM4SAM)이 훨씬 유리할 듯.