Annotation Flows of Recent RVOS Papers (Survey)
- VISA에는 언급이 없음
- VideoLISA에서는 안해도된다!!!!!!!!!!!!
Generation and Comprehension of Unambiguous Object Descriptions (CVPR 2016)
Generation and Comprehension of Unambiguous Object Descriptions
This paper introduces a method that can generate an unambiguous description of a specific object or region in an image.
Motivation
This paper start with a problem that previous text generating methods are subjective and ill-posed. How can we say one sentence is better than other sentence to describe an image? To handle this problem, this paper make a criterion that a referring expression is considered to be good if it uniquely describes the relevant object or region within its context, such that listern can comprehend the description and then recover the location of the original object.
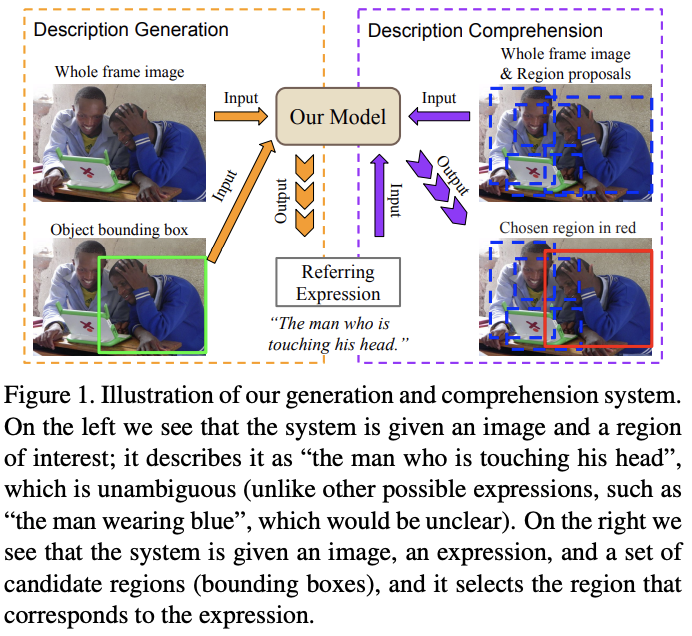
We formulate this problem, this paper split the generating expression problem into two subproblems: description generation and description comprehension. Description generation means that generate a good text description of an object or region in the images, and description comprehension for selecting the referred area(See Fig. 1).
Dataset Construction

They newly constructed referring expression dataset with MSCOCO. They selected objects if (1) there are between 2 and 4 instances of the same object type withing the same image, and (2) if their bounding boxes occupy at least 5% of image data. The total number of objects is 54,822 from 26,711 images. Then they used Mechanical Turk to check if the referring expression is good enough. If an expression is found that unambiguous so that the annotator could you point the object only using the expression, then they discarded it and re-annotated it. Consequently, they selected 104,560 expressions in total(See Fig. 2).
A closer look at referring expressions for video object segmentation (MTAP 2023)
A closer look at referring expressions for video object segmentation
The model introduced in this paper and experiments are beyond the scope of this post. One interesting point of this paper is that, this paper gives a categorization methods of referring expressions (RE).
Referring Expression Categorization
This paper argues that in order to make progress on VROS, benchmark datasets need to be challenging from both the visual and linguistic perspective. However, exisitng datasets such as Ref-DAVIS-17 show a single object in the scene or different objects from different classes. On the other hand, RVOS datasets like A2D Sentences often use object attibutes can only be already captured by a single frame, or not even true for the whole clip.
→ I totally agree with this statements.
So, in this paper, the researchers divided existing video object segmentation datasets with respect to the difficulty of referring expressions and the kind of semantic information they provide.
Difficulty and Correctness of Datasets
Firstly, each objects are classified into trivial or non-trivial. If there is only one object same to the referred object class, then the RE is trivial, and otherwise nontrivial. Secondly, a RE is marked as ambiguous when there is more than two object that can be referred by it. Finally, a RE is incorrect(wrong) when it is not match to the referred object.
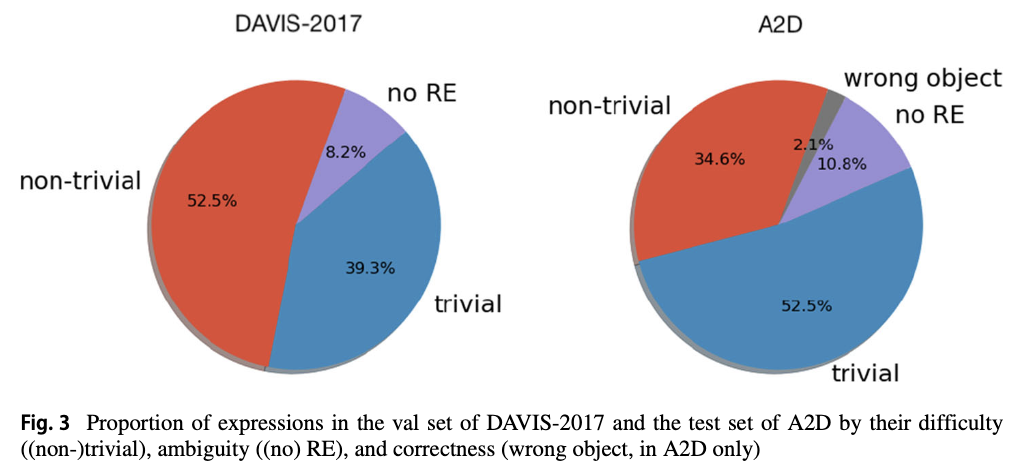
Ref-DAVIS-2017 and A2D are evaluated by using the criteria(See Fig. 1).
→ The source of REs are somewhat unclear to me. It seems that they got RE of DAVIS-2017 from the ACCV paper, but I’m not sure whether the A2D is same to the A2D Sentences which is published CVPR.
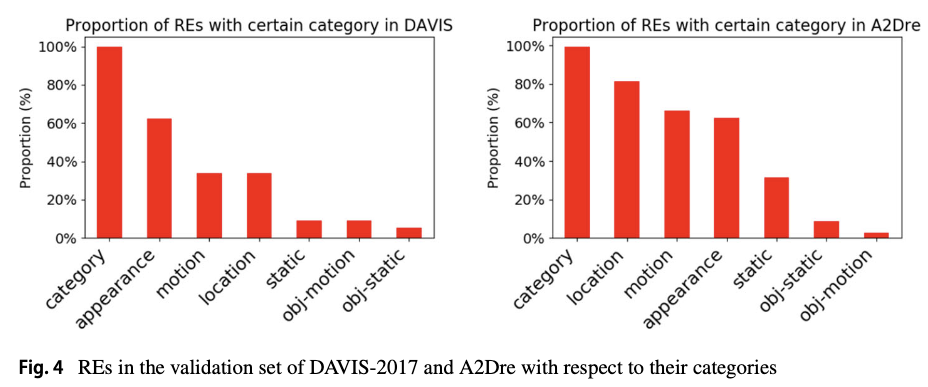
Semantic Categorization of REs

Tab.1 shows how they divided the annotations accoridng to the linguistics and situations.
Reducing the Annotation Effort for VOS Dataset (WACV 2021)
TL;DR You can generate VOS annotation using only bbox and bbox-to-seg model.
- Generating masks for every single frame is not scalable for a large-scale dataset.
- Introduce a CNN-based approach to label a pixel using bboxes.
- Just a single mask is sufficient to generate pseudo-labels to train VOS methods.
Motivation
- Densely labeling all frames in a video with segmentation masks is not necessary; annotating bounding box is sufficient.
- Annotating a single frame of an object is sufficient.
- Introduce TAO-VOS benchmark, obtained by applying the strategy to Tracking Any Object (TAO) dataset.
Reducing the Annotation Effort for VOS
In this section, this paper shows that bounding box annotations are sufficient to generate segmentation mask annotations.
Creating Pseudo-Labels from Boxes
By using Box2Seg method, they converted bounding boxes into segmentation masks. To get better results, they fine-tuned the Box2Seg model using the first-frame mask annotations. They named the generated segmentation masks as pseudo-labels, and found that they can get competitive results using the pseudo-labels for training.
Learning the What and How of Annotation in Video Object Segmentation (WACV 2024)
- Propose EVA-VOS, a human-in-the-loop annotation framework for VOS. what is human-in-the-loop?
Motivation
Since generating VOS mask is too expensive and tedious. Previous researchs approached by
- sparsely annotating large VOS datasets(22,29,59,77,80) → not accurate, limited use
- Accelerating the annotation process(interpolation, interactive seg, etc.).

To overcome limitations of previous annotation methods, they propose EVA-VOS, a human-in-the-loop pipeline. The agents predicts iteratively which frame should be annotated and which annotation type should be used.
For frame selection, a model is trained to regress the quality of a segmentation mask. And then selected the frame that has the maximum distance from its closest pre-annotated frame.
→ Annotate when scene is severly changes.
For the annotation selection, they used annotation type as action and $\frac{\text{segmentation quality improvement}}{\text{annotation time of the annotation type}}$ as a reward.
Then they tested this annotation precedure to annotate MOSE and DAVIS datasets, then showed significant improvement in terms of annotation time.
Method
