Taming Tranformers for High-Resolution Image Synthesis

Motivation
- Goal: combine the inductive bias of CNNs with the expressivity of transformers
- use a convolution to learn a codebook to encode visual information
- use a tranformer to model the long-range interactions between the tokens
- use a GAN to ensure that the dictionary captures information well
Method
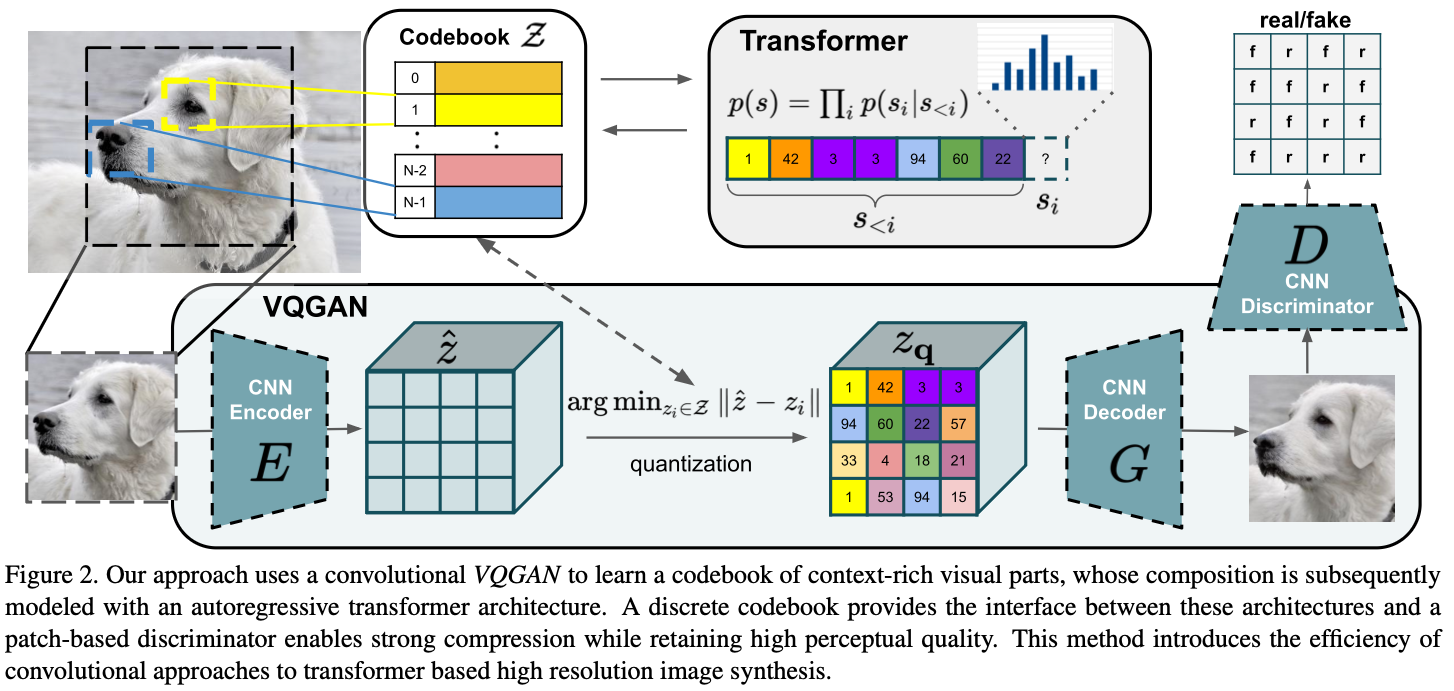
Learning an Effective Codebook of Image Constituents for Use in Transformers
To use a transformer, an image should be transformed into a sequence
Use a codebook to enable this 1
Make two models, an encoder $E$ and a decoder $G$, which are CNNs.
- $$ \mathbf{z}_q = \mathbf{q}(\hat{\mathbf{z}}) := \left( \arg\min_{z_k \in \mathcal{Z}} \left\| \hat{z}_{ij} - z_k \right\| \right) \in \mathbb{R}^{h \times w \times n_z} $$
Then get the reconstructed image $\hat x \approx x$ by
The final loss funtion is as follows:
$$ \mathcal{L}_{\text{VQ}}(E, G, \mathcal{Z}) = \\ \|x - \hat{x}\|^2 + \|\text{sg}[E(x)] - z_q\|_2^2 + \|\text{sg}[z_q] - E(x)\|_2^2 $$For the details of this loss function, please refer VQ-VAE.
- Learning a Perceptually Rich Codebook
- rather than using a pixelCNN, use Transformer to model $p(z)$
- replace L2 loss in reconstruction error to a perceptual loss using a discriminator
- The complete objective is:
$$ \mathcal{Q}^* = \arg\min_{E, G, \mathcal{Z}} \max_D , \mathbb{E}{x \sim p(x)} \left[ \mathcal{L}{\text{VQ}}(E, G, \mathcal{Z})
- \lambda \mathcal{L}_{\text{GAN}}({E, G, \mathcal{Z}}, D) \right] $$
This is a simple switching from L2 reconstruction error to Discriminator loss.
And the $\lambda$ is computed as:
- It is a scaling between the reconstruction loss and the GAN loss
- $L_{rec}$ is the perceptual reconstruction loss
Learning the Composition of Images with Transformers
Latent Transformers
- To generate an image, we gotta sample a plausible $z$ sequence
- Rather than using the PixelCNN, this paper uses the transformer
- predict the distribution of possible next indices, i.e. $p(s_i, s_{
- $p(s)$ is modeled as $\prod_i p(s_i|s_{
- $p(s)$ is modeled as $\prod_i p(s_i|s_{
Conditioned Synthesis
- for conditioned image generation,
Discussion
at that time, the Vision Transformer is not released yet. the two papers are released almost at the same time. So, this paper has a similar goal to the vision transformer paper. ↩︎