Motivation
The sense of Object Permanence (OP) is understanding that objects continue to exist and preserve their physical characteristics, even if they are not perceived directly.
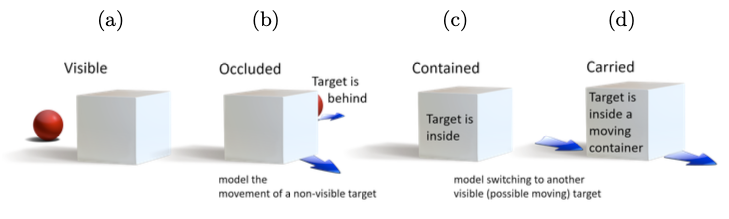 Figure 1: Inferring object location in rich dynamic scenes involves four different tasks, and two different types of reasoning.
Figure 1: Inferring object location in rich dynamic scenes involves four different tasks, and two different types of reasoning.
In this paper, the authors classifies the OP problem into four problems. Fig. 1 shows that reasoning about the location of a target object involves different subtasks of increasing complexity.
- Visible: trivial problem to solve
- Occlusion: detect a target object which becomes transiently visible
- Containment: a target object may be located inside an other container object and become non-visible
- Carried: inferring the location of a non-visible object located inside a moving containing object
** -> We have to notice that the containment scenario not only occurs when a target object get entered to somewhere; it occurs the natural chracteristic of camera!**
In this paper, the authors hypothesize that the occlusion scenario and containing scenario are completely different in its nature, hence they must be dealt very differently.
So, they introduce an unified architecture that is comprised of two reasoning modules to address the two scenarios.
Finally, they also introduce a new dataset called LA-CATER, which is designed to assess the model’s ability of localization object in the OP problem.
Method
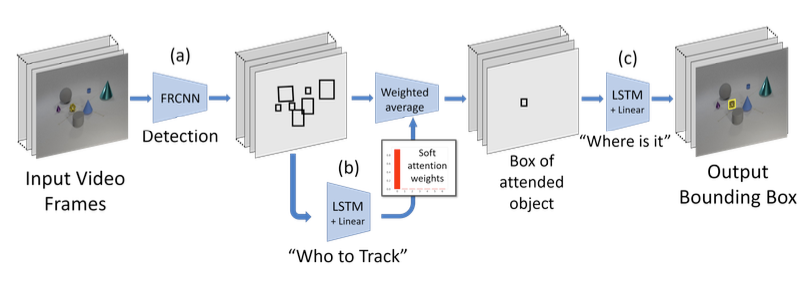 Figure 2: The architecture of the Object-Permanence network(OPNet)
Figure 2: The architecture of the Object-Permanence network(OPNet)
Actually the model is a little bit outdated, so let’s breifly overview the pipeline.
Perception and detection module. Firstly, using R-CNN family module, detect object from the given frame. Who to track module. Then using LSTM layers, output a distribution what object to track. Where is it module The second LSTM layers and a projection matrix predict target localization.
The LA-CATER Dataset
The dataset is based on the CATER dataset, which is made using the Blender 3D engine. LA-CATER includes a total number of 14K videos lasting 10-second long and containing 5 to 10 objects.
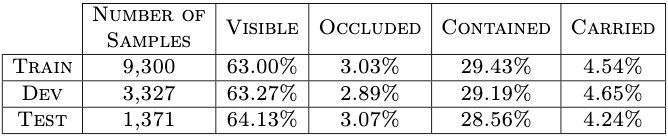 Table 1: Fraction of frames per type in the train.
Table 1: Fraction of frames per type in the train.
Experiments
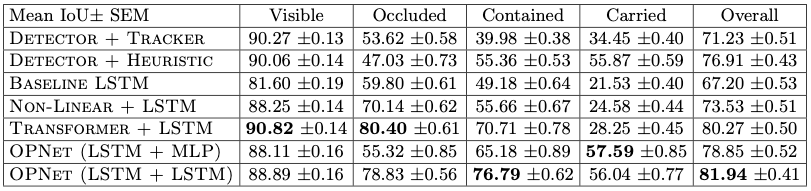 Table 2: Mean IoU on LA-CATER test data.
Table 2: Mean IoU on LA-CATER test data.
 Figure 3: Example of a success case (top row) and a failure case (bottom row)
Figure 3: Example of a success case (top row) and a failure case (bottom row)
Discussion
- this paper introduces an interesting setting of understanding objects and real-world scerios
- only conducted under lab-level scenarios
- not clear why LSTM-based model works and how they actually works
- I think the most important occlusion scenario is video frame-related occlusions