Generation Process
Generation은 $x\sim p(x)$를 sample하는 stochastic process이다.
따라서 $p(x)$를 근사하는 $p_{data}(x)\approx p_θ(x)$를 학습한다.
- 그 후 $x~\in p_θ(x)$을 수행하여 sample한다.
그러나 일반적으로 $p_θ(x)$를 직접 만드는 것은 어려움.
- dimension이 지나치게 큼.
- 따라서 latent variable $z$를 도입해 $p(x|z)$를 근사함.
Variational Inference
- variational inference는 observation $x$로부터 latent variable $z$를 찾는 것을 의미한다.
- “variational"은 함수 f를 optimize하는 과정을 의미함. 여기서는 $q$를 optimize함.
- posterior distribution $p(z|x)$를 구하는 문제와 같다.
- 일반적으로 이는 denominator가 intractable하므로 실제로 구할 수는 없다.
- 그래서 이를 tractable한 $q(z)$로 approximate하고, 둘의 KL divergence를 minimize하는 것을 목표로 한다.
- 이를 minimize하는 q(z)를 찾는 것이 variational inference의 목표이다.
Evidence Lower Bound (ELBO)
$$\log p(x) = ELBO(q) + KL(q(z) || p(z|x))$$$$ELBO(q) = \mathbb E_{q(z)} \left[ \log p(x,z) - \log q(z)\right]$$
Denoising Diffusion Probabilistic Models (DDPM)
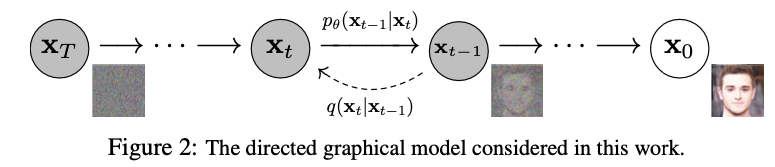
- diffusion probabilistic model은 variational inference를 이용하여 학습된 parameterized Markov chain
- data에 matching되는 sample을 finite time 이후에 생성함.
Background
- $x_0$는 original image, $x_T$는 noised image이다.
- Diffusion model은 $p_\theta(\mathbf{x}_0) := \int p_\theta(\mathbf{x}_{0:T}) \, d\mathbf{x}_{1:T}$인 latent variable model이다.
- 각각의 $x_1,\dots, x_T$는 latent인데, 원본 데이터 $x_0$와 same dimension을 가진다.
- joint distribution $p_θ(x_{0:T})$는 reverse process이다.
- 이는 $p(x_T)=\mathcal{N} (x_T;0,I)$에서 시작하는 Gaussian transition으로 학습된 markov chain으로 정의된다.
- Gaussian Transition markov chain이라는 것은, 다음 상태가 이전 상태를 param으로 가지는 Gaussian에서 sample됨을 의미하는 것이다.
- 이는 $p(x_T)=\mathcal{N} (x_T;0,I)$에서 시작하는 Gaussian transition으로 학습된 markov chain으로 정의된다.
- reverse process의 joint distribution과 markov transition은 다음과 같이 정의된다:
$p_\theta$는 0부터 T까지의 process에 대한 확률분포이다. 이는 $x_T$부터 $x_0$의 full sequence에 대한 joint probability이다. isotrophic Gaussian $x_T\sim \mathcal {N}(0,I)$에서 첫 noised image를 sample하고, 나머지는 Gaussian transition의 markovian chain으로 연결되는 구조이다.
- forward process 또는 diffusion process는 다음과 같이 정의된다. $$ q(\mathbf{x}_{1:T} \mid \mathbf{x}_0) := \prod_{t=1}^T q(\mathbf{x}_t \mid \mathbf{x}_{t-1}), \quad q(\mathbf{x}_t \mid \mathbf{x}_{t-1}) := \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I}) $$
원본 이미지가 주어졌을 때 variance schedule $β_1, \dots, β_T$에 따라서 Gaussian noise를 더하는 과정이다. 이때의 Markov chain은 fix된 것이다. 이때 $\sqrt {1-\beta_t}$ 로 mean이 scale되고, variance는 $\beta_t$로 scale된다. 이떄 $\beta_t$는 $t$가 증가할수록 monotically increase하는 함수이다. 초반 step에는 작은 $\beta_t$를 갖고, 뒤쪽 step에는 큰 $\beta_t$를 써서 pure Gaussian noise에 가까운 모습이 된다.
- variational lower bound는 다음과 같고, 이를 이용해 train한다. $$ \mathbb{E}[-\log p_\theta(\mathbf{x}_0)] \leq \mathbb{E}_q \left[ - \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \mid \mathbf{x}_0)} \right] = \mathbb{E}_q \left[ - \log p(\mathbf{x}_T) - \sum_{t \geq 1} \log \frac{p_\theta(\mathbf{x}_{t-1} \mid \mathbf{x}_t)}{q(\mathbf{x}_t \mid \mathbf{x}_{t-1})} \right] =: \mathcal{L} $$
원래 marginal likelihood $\log p_θ(x_0)$를 알면 곧바로 generation을 할 수 있어 좋겠지만, 이는 모든 x에 대해서 jointly 적분한 값 $p_θ(x_0) = \int{p_θ(x_{0:T})} dx_{1:T}$은 $T$개의 연속된 변수에 대해 full dependency를 가정하여 계산되어야 하므로 intractable하다.
따라서 여기에서 간단한 Markov property에 대한 가정을 넣을 수 밖에 없다. Markov chain으로 전체 marginal likelihood를 $T$개의 다음 step을 sampling하는 것으로 surrogate를 만들면 훨씬 간단한 다음 구조가 된다:
$$p_θ(x_{0:T}) = p(x_T) \prod ^T_{t=1} p_θ(x_{t-1} | x_t)$$다시 원래 식을 보면, variational lower bound는 두 개의 term으로 구성된다. 왼쪽 term은 $x_T$의 probability distribution인데 이건 VAE에서의 $p(z)$에 해당하는 것이다. 이는 Gaussian noise를 전제한다.
또한 forward process에서 임의의 timestep $t$에서의 $\mathbf{x}_t$를 sampling하는 likelihood를 closed form으로 쓸 수 있다. 만약 $\alpha_t := 1 - \beta_t$ and $\bar{\alpha}_t := \prod_{s=1}^{t} \alpha_s$라고 하면 다음과 같다:
$$q(\mathbf{x}_t | \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t) \mathbf{I})$$- 증명 필요
Diffusion Models and Denoising Autoencoders
Forward Process and $L_T$
Reverse Process
DDPM Objective
- DDPM Appendix A에 나와 있는 내용이다.
$$ \begin{align*}
\log p_\theta(x_0) &= - \log \int_{x_{1:T}} p_\theta(x_{0:T}) , dx_{1:T} \ &= - \log \int_{x_{1:T}} p_\theta(x_{0:T}) \frac{q(x_{1:T} \mid x_0)}{q(x_{1:T} \mid x_0)} , dx_{1:T} \ &= - \log \mathbb{E}{x{1:T} \sim q(x_{1:T} \mid x_0)} \left[ \frac{p_\theta(x_{0:T})}{q(x_{1:T} \mid x_0)} \right] \ &\leq \mathbb{E}q \left[ - \log \frac{p\theta(x_{0:T})}{q(x_{1:T} \mid x_0)} \right] \quad \text{Jenson’s inequality}\ &= \mathbb{E}q \left[ - \log p(x_T) - \sum{t=1}^T \log \frac{p_\theta(x_{t-1} \mid x_t)}{q(x_t \mid x_{t-1})} \right] \ &=\mathbb{E}q \Bigg[ - \log p(\mathbf{x}T) - \sum{t > 1} \log \frac{p\theta(\mathbf{x}_{t-1} \mid \mathbf{x}t)}{q(\mathbf{x}{t-1} \mid \mathbf{x}_t, \mathbf{x}0)} \cdot \frac{q(\mathbf{x}{t-1} \mid \mathbf{x}_0)}{q(\mathbf{x}_t \mid \mathbf{x}0)} - \log \frac{p\theta(\mathbf{x}_0 \mid \mathbf{x}_1)}{q(\mathbf{x}_1 \mid \mathbf{x}_0)} \Bigg] \ &= \mathbb{E}_q \Bigg[ - \log \frac{p(\mathbf{x}T)}{q(\mathbf{x}T \mid \mathbf{x}0)} - \sum{t > 1} \log \frac{p\theta(\mathbf{x}{t-1} \mid \mathbf{x}t)}{q(\mathbf{x}{t-1} \mid \mathbf{x}_t, \mathbf{x}0)} - \log p\theta(\mathbf{x}_0 \mid \mathbf{x}_1) \Bigg] \ &= \mathbb{E}q \Bigg[ D{\mathrm{KL}}(q(\mathbf{x}T \mid \mathbf{x}0) ,|, p(\mathbf{x}T)) + \sum{t > 1} D{\mathrm{KL}}(q(\mathbf{x}{t-1} \mid \mathbf{x}t, \mathbf{x}0) ,|, p\theta(\mathbf{x}{t-1} \mid \mathbf{x}t)) - \log p\theta(\mathbf{x}_0 \mid \mathbf{x}_1) \Bigg] \end{align*} $$
first term은 $p(x_T):=\mathcal{N}(x_T;0,I)$로 fix하므로 constant이다.
second term은 forward posterior와 model의 KL divergence이다.
Dicussions
- 왜 markov하게 정의하는지?
- 해결됨
- Gaussian noise를 더하면 Gaussian이 되나? 증명 필요