LV-HayStack
Re-thinking Temporal Search for Long-Form Video Understanding (CVPR 2025)
publish: Apr 3 2025
temporal search를 Long Video Haystack problem으로 바꿈
- relevant frame의 minimal set을 찾는 문제
LV-Haystack dataset 도입
- 480h video, 15,092 annotated instances
$T^*$ framework 제안 (Fig. 2 참조)
- question grounding, iterative temporal search, downstream task completion의 세 단계로 구성
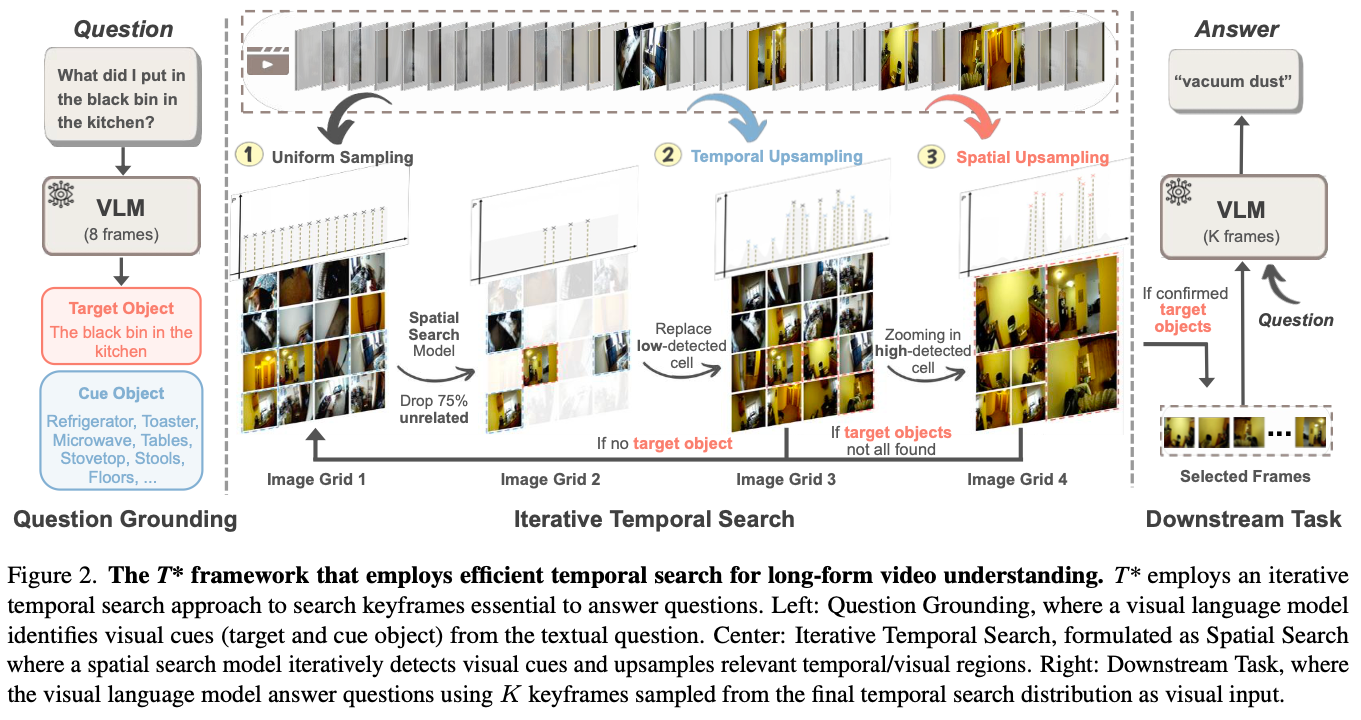
- question grounding, iterative temporal search, downstream task completion의 세 단계로 구성
Question Grounding
- text와 video를 보고 cue object를 찾는 과정
- video V에서 fixed interval에 대해서 N개의 frame을 뽑음
- 그 안에서 VLM이 target objects T와 cue objects C를 추출
Iterative Temporal Search
- Initialization
- 모든 frame에 대해서 uniform probability distribution을 initialize
- object마다 weight 설정 -> target은 1, cue는 0.5
- Frame Sampling and Grid Construction
- PDF $P$에 따라서 frame sampling
- sample된 frame을 grid layout $G$ sized g×g에 배치
- Object Detection and Scoring
- frame된 image에서 object detection
- sufficient confidence로 target object가 detect되면 keyframe set에 추가
- Distribution Update
- spline-based interpolation으로 distribution update
- temporal locality를 위해서 window-based update
- Initialization